# 浏览器缓存
浏览器缓存,也称客户端缓存或http(协议层)缓存。
http缓存是保存资源副本的技术,复用资源,提高网站性能,减少等待时间和网络流量。Web缓存发现请求的资源已被存储,拦截请求,返回缓存数据,不会取服务器重新下载,缓解服务器压力,提高性能。分两大类:私有与共享缓存。包括浏览器缓存,代理缓存,网关缓存,CDN,反向代理缓存,负载均衡缓存等。私有缓存(浏览器缓存);共享缓存(代理缓存)
# 浏览器缓存机制
强缓存优先级高于协商缓存;强缓存中 Cache-Control 优先级高于 Expires
强缓存
强缓存命中不会发送请求到服务端,直接从本地缓存中获取资源。返回状态码200(from memory cache/from disk cache)
强缓存利用
Cache-Control和Expires两个字段实现,表示资源在客户端的缓存有效期。协商缓存(对比缓存)
协商缓存会发送请求到服务端,服务端通过请求头的头部字段验证是否命中协商缓存。如果命中,服务器会将这个请求返回,但是不会返回这个资源的实体,而是返回状态码304(not modified),通知浏览器从缓存中获取资源。
协商缓存是利用的是
Last-Modified, If-Modified-Since和ETag, If-None-Match这两对字段来管理的。
先试图命中强缓存,然后再试图命中协商缓存。强缓存与协商缓存的共同点是:如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;区别是:强缓存不发请求到服务器,协商缓存会发请求到服务器。当协商缓存也没有命中的时候,浏览器直接从服务器加载资源数据。
# 浏览器缓存控制
浏览器是否使用缓存、缓存多久,是由服务器控制的。服务器发回的响应的「响应头」部分的某些字段指明了有关缓存的关键信息。
1. 通用首部字段(请求报文与响应报文都携带)
| 字段 | 说明 |
|---|---|
| Cache-Control | http1.1 控制缓存行为 |
| Pargma | http1.0 的产物,值为'no-cache'时禁止缓存,不能替代cache-control,目前的作用是向后兼容 |
常见的 Cache-Control 字段
| 值 | 说明 |
|---|---|
| no-store | 绝对禁止缓存(禁止强缓存与协商缓存)。不存储客户端服务端任何内容,客户端都会下载完整的响应内容 |
| no-cache | 缓存但重新验证(禁止强缓存)(带本地缓存相关验证字段访问服务器,服务端验证缓存是否过期,未过期返回304,这时候缓存才使用本地缓存副本)先验证->304->使用本地缓存 |
| private | 私有缓存(响应只能用于浏览器私有缓存中)中间人(CDN,代理不能缓存), 如果要求 HTTP 认证,响应会自动设置为 private。 |
| public | 公共缓存(可以被任何中间人缓存), 多用户间共享。 |
| max-age | 单位:秒(s)。资源能够被缓存(保持新鲜)的最大时间;相对于Expires,是一个相对时间,优先级高于 Expires,max-age是距离请求发起的时间的秒数,针对那些不会改变的文件(静态资源),可手动设置一定的时长缓存 |
| s-maxage | 单位:秒(s)。只用于共享缓存(如:CDN缓存)。s-maxage有效期内不请求CDN。 max-age 用于普通缓存,而 s-maxage 用于代理缓存。如果存在 s-maxage,则会覆盖掉 max-age 和 Expires |
| must-revalidate | 缓存使用陈旧资源时必须先验证状态,已过期的缓存不被使用 |
2. 请求首部字段
| 字段 | 说明 |
|---|---|
| If-Match | 比较ETag是否一致 |
| If-None-Match | 比较ETag是否不一致 |
| If-Modified-Since | 比较资源最后更新时间是否一致 |
| If-Unmodified-Since | 比较资源最后更新时间是否不一致 |
3. 响应首部字段
| 字段 | 说明 |
|---|---|
| ETag | 强校验器。如果资源请求的响应头里含有ETag, 客户端可以在后续的请求的头中带上 If-None-Match 头来验证缓存 |
4. 实体首部字段
| 字段 | 说明 |
|---|---|
| Expries | http1.0 产物,实体过期时间,绝对时间,服务器返回,缓存最理想的情况,因为不会发出请求,所以后端也就无需考虑查询快慢。 |
| Last-Modified | 弱校验器。资源最后一次修改的时间,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存 |
# 强缓存过程
强缓存利用Cache-Control和Expires两个字段实现,表示资源在客户端的缓存有效期。
# 利用 Expires 字段的强缓存
- 浏览器第一次请求服务器的资源,服务器在返回这个资源时,在响应头中加 Expires 字段。
- 浏览器接受此资源,会将此资源以及响应头一起缓存(引出: 缓存命中的请求返回的 header 不是来自服务端,而是来自之前缓存的header)。
- 浏览器再请求此资源时,会先从缓存中找,找到后,拿 Expires 和当前的请求时间比较,如果请求时间小于 Expires,就能命中缓存,否则没命中。
- 如果没命中,浏览器直接从服务器加载资源时,Expires 重新加载的时候会被更新。
缺点:
http1.0 的产物,由于它是服务器返回的一个绝对时间,在服务器时间与客户端时间相差较大时,缓存管理容易出现问题。(比如:随意修改下客户端时间,就能影响缓存命中的结果)。所以在 HTTP 1.1 的时候,提出了一个新的 header,就是 Cache-Control,这是一个相对时间,在配置缓存的时候,以秒为单位,用数值表示。
# 利用 Cache-Control 字段的强缓存
- 浏览器第一次请求服务器的资源,服务器在返回这个资源时,在响应头中加 Cache-Control 字段。
- 浏览器接受此资源,会将此资源以及响应头一起缓存(引出: 缓存命中的请求返回的 header 不是来自服务端,而是来自之前缓存的header)。
- 浏览器再请求此资源时,会先从缓存中找,找到后,根据它第一次的请求时间和 Cache-Control 设定的有效期,计算出一个资源过期时间,再用这个过期时间和当前请求时间比较,如果请求时间小于资源过期时间,就能命中缓存,否则没命中。
- 如果没命中,浏览器直接从服务器加载资源时,Cache-Control 重新加载的时候会被更新。
Cache-Control 描述的是一个相对时间,在进行缓存命中的时候,都是利用客户端时间进行判断,所以相比较 Expires,Cache-Control 的缓存管理更有效,安全一些。
Cache-Control 优先级高于 Expires
没有命中强缓存就会发一个请求到服务器,验证协商缓存是否命中,如果协商缓存命中,请求响应返回的 http 状态为 304 并且会显示一个 Not Modified 的字符串
# 协商缓存过程
协商缓存是利用的是Last-Modified, If-Modified-Since 和ETag, If-None-Match这两对字段来管理的。
# Last-Modified & If-Modified-Since 控制的协商缓存
- 浏览器第一次请求服务器的资源,服务器在返回这个资源时,在响应头中加 Last-Modified 字段,表示这个资源在服务器上最后的修改时间。
- 浏览器再次请求此资源时,会在请求头加 If-Modified-Since 字段,值等于上次请求时的 Last-Modified 的值。
- 服务器再次收到资源请求时,会根据请求头的 If-Modified-Since 和资源在服务器上的最后修改时间判断资源是否有变化,如果没有变化返回 304(Not Nodified),但不会返回资源内容;如果有变化,则正常返回资源。当服务器返回304的响应时,响应头不会再添加 Last-Modified ,因为资源没有变化,那么 Last-Modified 也不会变化,即不更新 Last-Modified
- 浏览器收到 304 响应后,就会从缓存中加载资源。
- 如果协商缓存没有命中,浏览器直接从服务器加载,Last-Modified 会被更新,下次请求时,If-Modified-Since 会使用上次返回的 Last-Modified 。
Last-Modified 的弊端
- 如果本地打开缓存文件,即使没有对文件进行修改(文件内容没有变化),但还是会造成 Last-Modified 被修改,服务端不能命中缓存导致发送相同的资源
- 因为 Last-Modified 只能以秒计时,如果在不可感知的时间内修改完成文件,那么服务端会认为资源还是命中了,不会返回正确的资源
- 有些服务器无法精准获取文件的最后修改时间
Last-Modified & If-Modified-Since 都是服务端响应头返回的字段,一般来说,在没有调整服务器时间和篡改客户端缓存的情况下,这两个字段配合起来管理协商缓存是非常可靠的,但是有时候会存在服务器上资源其实有变化,但是最后修改时间却没有变化的情况,而这种问题又很不容易被定位出来,而当这种情况出现的时候,就会影响协商缓存的可靠性。所以就有了另外一对ETag, If-None-Match来管理协商缓存。
# ETag & If-None-Match 控制的协商缓存
- 浏览器第一次请求服务器的资源,服务器在返回这个资源时,在响应头中加 ETag 字段,ETag 是服务器根据当前请求的资源生成的一个唯一标识,这个唯一标识是一个字符串,只要资源有变化这个串就会不同,跟最后修改时间没有关系,所以能很好的补充 Last-Modified 的问题
- 浏览器再次请求此资源时,会在请求头加 If-None-Match 字段,值等于上次请求时的 ETag 的值。
- 服务器再次收到资源请求时,会根据请求头的 If-None-Match 和 服务端再根据资源生成的新的 ETag 比较,如果没有变化返回 304(Not modified),但是不会返回资源的内容;如果有变化,就正常返回资源。与 Last-Modified 不一样的是,当服务器返回 304 的响应时,由于 ETag 重新生成过,响应头中还会把这个 ETag 返回,即使这个 ETag 跟之前的没有变化。
- 浏览器收到 304 响应后,就会从缓存中加载资源。
Etag 和 Last-Modified 非常相似,都是用来判断一个参数,从而决定是否启用缓存。但是 ETag 相对于Last-Modified 也有其优势,可以更加准确的判断文件内容是否被修改,从而在实际操作中实用程度也更高。如果两个都支持的话,服务器会优先选择 ETag
协商缓存跟强缓存不一样,强缓存不发请求到服务器,所以有时候资源更新了浏览器还不知道,但是协商缓存会发请求到服务器,所以资源是否更新,服务器肯定知道。大部分web服务器都默认开启协商缓存,而且是同时启用Last-Modified & If-Modified-Since 和 ETag & If-None-Match,同时开启是为了处理 Last-Modified 不可靠的问题。
协商最佳实践
- 如果使用 Last-Modified 不会出现任何问题,可以直接移除 ETag,google 的搜索首页则没有使用 ETag。
- 确定要使用 ETag,在配置 ETag 的值的时候,移除可能影响到组件集群服务器验证的属性,例如只包含组件大小和时间戳。
注意
分布式系统里多台机器间文件的 Last-Modified 必须保持一致,以免负载均衡到不同机器导致比对失败。
分布式系统尽量关闭掉 ETag(每台机器生成的 ETag 都会不一样)。
对比
- 在精准度上,ETag 优于 Last-Modified。优于 ETag 是按照内容给资源上标识,因此能准确感知资源的变化。而 Last-Modified 就不一样了,它在一些特殊的情况并不能准确感知资源变化,主要有两种情况:
- 编辑了资源文件,但是文件内容并没有更改,这样也会造成缓存失效。
- Last-Modified 能够感知的单位时间是秒,如果文件在 1 秒内改变了多次,那么这时候的 Last-Modified 并没有体现出修改了。
- 在性能上,Last-Modified 优于 ETag,也很简单理解,Last-Modified 仅仅只是记录一个时间点,而 Etag 需要根据文件的具体内容生成哈希值。
# 缓存实践
缓存的意义就在于减少请求,更多地使用本地的资源,给用户更好的体验的同时,也减轻服务器压力。所以,最佳实践,就应该是尽可能命中强缓存,同时,能在更新版本的时候让客户端的缓存失效。
在更新版本之后,如何让用户第一时间使用最新的资源文件呢?机智的前端们想出了一个方法,在更新版本的时候,顺便把静态资源的路径改了,即,可以利用 webpack 的文件指纹策略。这样,就相当于第一次访问这些资源,就不会存在缓存的问题了。
一个较为合理的缓存方案:
- HTML:使用协商缓存。
- 假设 html 使用了强缓存,当我们重新上线 css、js等文件,html文件(因为css改变了,所以html要重新引入css文件,因此html也要改并且重新上线),但是 html 使用的是强缓存,在缓存期间浏览器直接从强缓存中读取html文件,以至于你重新上线了但是还是原来的 html,内容还是原来,必须要用户强制刷新才会有新内容出现,这就不合理。所以不能使用强缓存。
- CSS、JS、图片:使用强缓存,且文件命名带上 hash 值。
- 更新资源发布路径以实现非覆盖式发布,使强缓存失效。
- 利用版本号更新策略可行吗?
<link rel="stylesheet" href="/index.css?v=1.0.2">在后面加个版本号,因为每次 html 都会发送请求询问是否过期,所以就可以达到缓存更新效果。但是开发不可能就引用一个 css 文件,往往是多个的。每次修改一个css 文件,其余的版本也要跟着升级,没有必要。
既然可以使用协商缓存的 Etag,那有必要使用文件指纹吗?
- 缓存的意义。缓存的意义就在于减少请求,更多地使用本地的资源,给用户更好的体验的同时,也减轻服务器压力。所以,最佳实践,就应该是尽可能命中强缓存,同时,能在更新版本的时候让客户端的缓存失效,访问最新资源,那么就需要文件指纹、版本号等使强缓存失效的手段。
- CSS、js、图片、字体等资源要做强缓存。利用 Webpack 合理分包加上文件指纹做到客户端的持久化缓存,不去解析 DNS,不去请求服务器,减小服务端压力的同时提高用户体验。所以,文件指纹用于资源路径更新使缓存失效,达到及时拉取最新资源的目的,使用文件指纹和 Etag 没什么关系。
- 分布式服务不使用 Etag。分布式服务,Etag 是关闭的,因为每台机器生成的 ETag 都会不一样。
- 持久换缓存做无覆盖式更新。CSS、js、图片、字体等资源不需要做协商缓存,不需要每次请求服务器询问资源是否新鲜。只需要 hrml 做协商缓存即可。若发布了最新资源,由于 html 中引用的资源的路径变了,会拉取最新资源,做无覆盖式更新。
总之一句话,为减少服务器请求,资源要尽可能做强缓存,而资源的更新需要利用文件指纹变更资源路径使强缓存失效,从而达到及时拉取到最新资源的目的。所以,文件指纹是为强缓存资源服务的,与协商缓存 Etag 无任何关系。
# 浏览器缓存流程图
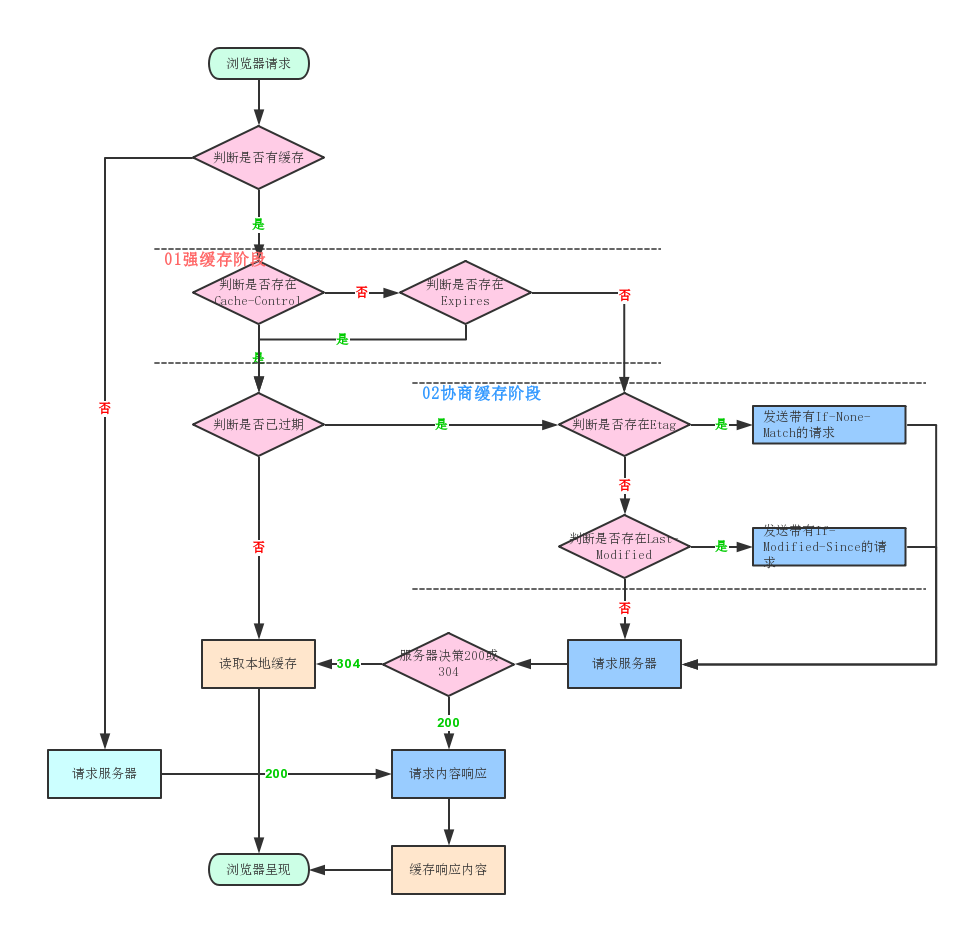
# 浏览器缓存位置
从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络。
- service worker
- memory cache
- disk cache
- push cache
# service worker
Service Worker 借鉴了 Web Worker 的 思路,即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问 DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能。其中的离线缓存就是 Service Worker Cache。Service Worker 同时也是 PWA 的重要实现机制。
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。
Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。
当 Service Worker 没有命中缓存的时候,我们需要去调用 fetch 函数获取数据。也就是说,如果我们没有在 Service Worker 命中缓存的话,会根据缓存查找优先级去查找数据。但是不管我们是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 Service Worker 中获取的内容。
# memory cache
Memory Cache 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。 一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
内存缓存中有一块重要的缓存资源是 preloader 相关指令(例如<link rel="prefetch">)下载的资源。 preloader 的相关指令已经是页面优化的常见手段之一,它可以一边解析 js/css 文件,一边网络请求下一个资源。
需要注意的事情是,内存缓存在缓存资源时并不关心返回资源的 HTTP 缓存头 Cache-Control 是什么值,同时资源的匹配也并非仅仅是对URL做匹配,还可能会对 Content-Type,CORS 等其他特征做校验。
# disk cache
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 Disk Cache
# push cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 Chrome 浏览器中只有 5 分钟左右,同时它也并非严格执行 HTTP 头中的缓存指令。
# 用户行为影响
| 行为 | Expires/Cache-Control | Last-Modified/Etag |
|---|---|---|
| 地址栏回车 | ✅ | ✅ |
| 页面链接跳转 | ✅ | ✅ |
| 新开窗口 | ✅ | ✅ |
| 前进回退 | ✅ | ✅ |
| F5刷新 | ✅ | ❎ |
| Ctrl+F5强制刷新 | ❎ | ❎ |
# 浏览器缓存总结
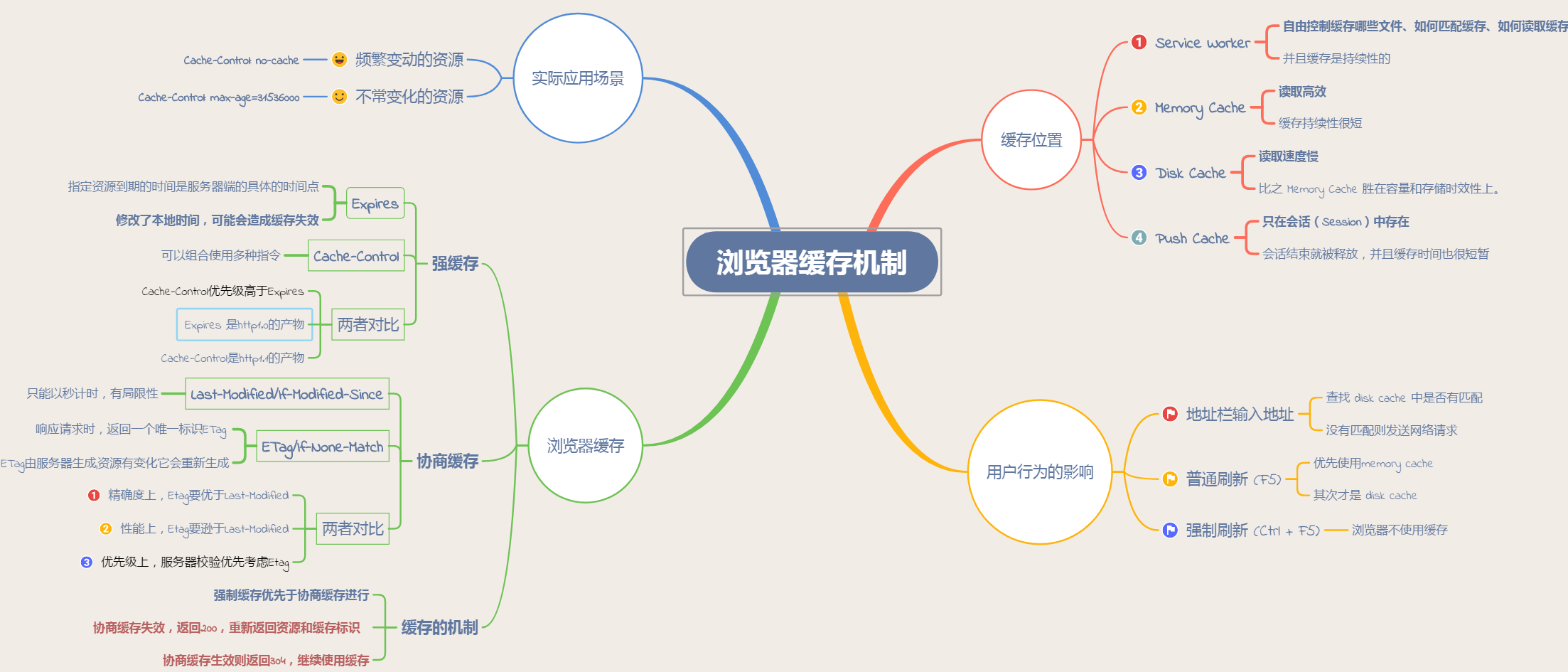
# 其他参考
(1.6w字)浏览器灵魂之问,请问你能接得住几个 (opens new window)
# isuess 问题
# Q1. no-cache和no-store 以及 max-age=0 的区别
- no-cache
Cache-Control 为 no-cache。表示必须重新去获取请求。由服务端来判断是否使用缓存, 即可以在本地缓存,可以在代理服务器缓存,但是这个缓存要服务器验证才可以使用
- no-store
是真正的不进行缓存。即彻底得禁用缓存,本地和代理服务器都不缓存,每次都从服务器获取
max-age=0
- max-age > 0 时。直接从浏览器缓存中提取。
- max-age <= 0 时。向服务端发送 http 请求确认,该资源是否有修改, 有的话返回 200 。没有返回 304。(即 max-age=0 表示不管 response 怎么设置,在重新获取资源之前,先检验 ETag/Last-Modified)
# Q2. 状态码为 200 from cache 和 304 Not modified 的区别
- 请求状态码为 200 from cache
表示该资源已经被缓存过,并且在有效期内,所以不再向浏览器发出请求,直接使用本地缓存。
- 状态码为 304 Not modified
表示浏览器虽然发现了本地有该资源的缓存,但是不确定是否是最新的,于是想服务器询问,若服务器认为浏览器的缓存版本还可用(即还未更新),那么便会返回 304,继续使用本地的缓存。