# 页面管理与跳转
# 初始化
# 启动过程
初次进入小程序的时候,微信客户端初始化好宿主环境,同时从网络下载或者从本地缓存中拿到小程序的代码包,把它注入到宿主环境。大概是这么个过程:
- 创建线程(渲染层和逻辑层),启动小程序。
- 载入基础库(WebView 基础库和 AppService 基础库)。
- 载入小程序业务代码(下载或者从本地缓存中拿到)。
- 使用
App()注册程序实例。
为了让小程序业务代码能够调用 API 以及组件,就需要在启动小程序后先载入基础库,接着再载入业务代码。 由于所有小程序都需要注入相同的基础库,所以小程序的基础库会被提前内置在微信客户端 。而基础库是热更新的,故一般等微信客户端携带上一个稳定版的基础库正式发布后,再进行新版本基础库的灰度和推送。
# 注册 App 实例
宿主环境提供了App()构造器用来注册一个程序 App。App 实例是单例对象,在其他 JS 脚本中可以使用宿主环境提供的getApp()来获取程序实例。App() 必须在 app.js 中调用,必须调用且只能调用一次。不然会出现无法预期的后果。App()函数用来注册一个小程序。接受一个Object参数,其指定小程序的生命周期回调等。小程序实例的生命周期如下:
# onLaunch
小程序初始化完成时(全局只触发一次)触发onLaunch回调。 在微信客户端中打开小程序有很多途径,对不同途径的打开方式,小程序有时需要做不同的业务处理。所以微信客户端会把打开方式带给onLaunch和onShow的调用参数options,我们可以根据参数来判断一些进入方式,以及做对应的逻辑处理。
例如,我需要拿到从另外一个小程序跳转过来携带的信息,此时场景值应该是 1037:
App({
// ...
onShow: function(e) {
if (e.scene === 1037) {
const data = e.referrerInfo && e.referrerInfo.extraData; // 拿到对应的数据
const refAppid = e.referrerInfo && e.referrerInfo.appId; // 拿到对应的小程序appid
}
}
});
2
3
4
5
6
7
8
9
# onShow
小程序启动,或从后台进入前台显示时触发onShow回调。通常我们用来处理数据和状态的更新。 小程序进入后台状态:当用户点击左上角关闭,或者按了设备 Home 键离开微信,小程序并没有直接销毁。
# onHide
小程序从前台进入后台时触发onHide回调。 小程序进入前台状态:当再次进入微信或再次打开小程序,又会从后台进入前台。
# 获取 App 实例
我们可以使用全局的getApp()函数来获取到小程序 App 实例(在App()内的函数中使用this就可以拿到app实例。)。
前面我们可以看到,App 的生命周期是由微信客户端根据用户操作主动触发的。故我们通过getApp()获取实例之后,不应该私自调用生命周期函数。
具体的原理是什么呢?小程序的 JS 脚本是运行在 JsCore 的线程里,小程序的每个页面各自有一个 WebView 线程进行渲染,所以**小程序切换页面时,小程序逻辑层的 JS 脚本运行上下文依旧在同一个 JsCore 线程中。**因此,App 构造器可以传递其他参数作为全局属性以达到全局共享数据的目的。
由于所有页面的脚本逻辑都跑在同一个 JsCore 线程,页面使用setTimeout或者setInterval的定时器,即使切换了页面,也需要自行清理定时器。可以选择:
- 在页面离开
onUnload、onHide等的时候自行清理 - 做全局的定时器管理(当然也还是需要关闭时清理)
# 页面生命周期
宿主环境提供了 Page(Object) 构造器用来注册一个小程序页面,接受一个 Object 类型参数,其指定页面的初始数据、生命周期回调、事件处理函数等。
注意:Object 内容在页面加载时会进行一次深拷贝,需考虑数据大小对页面加载的开销。
这里我们先来看看官方的生命周期图:
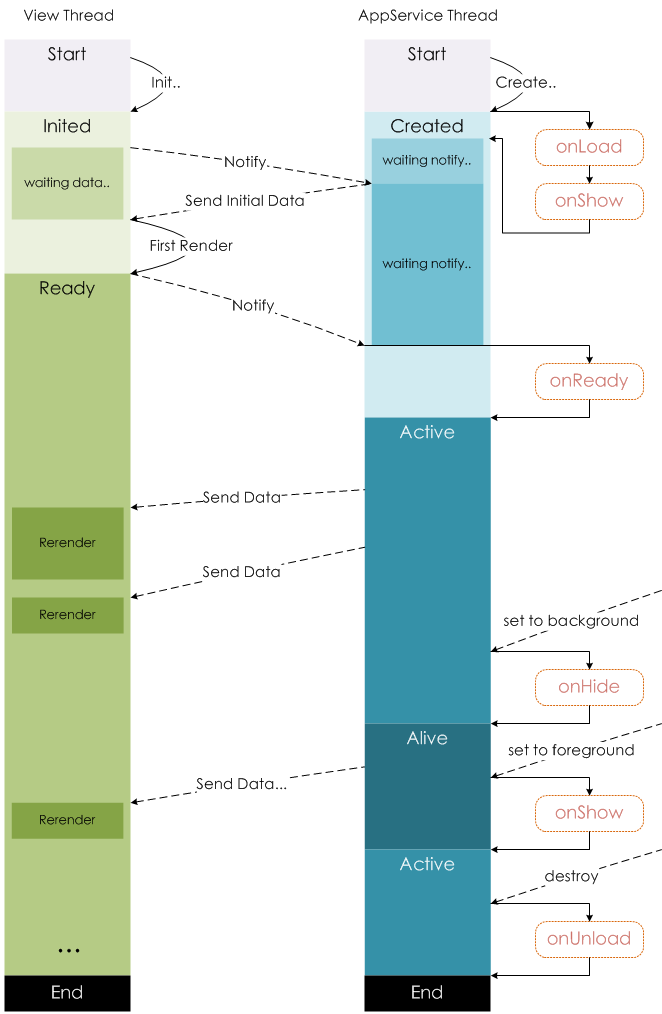
左侧是渲染层,右侧是逻辑层:
- 渲染层和逻辑层之间通信,是通过 Native 转发实现的。
- 逻辑层通过 Page 实例的
setData方法传递数据到渲染层。由于需要两个线程的一些通信消耗,为了提高性能,每次只设置需要改变的最小单位数据。 - 生命周期顺序:
onLoad->onShow->onReady
页面生命周期函数:
onLoad(Object query) 页面加载时触发。一个页面只会调用一次,可以在
onLoad的参数中获取打开当前页面路径中的参数。onShow() 页面显示/切入前台时触发。
onReady() 页面初次渲染完成时触发。一个页面只会调用一次,代表页面已经准备妥当,可以和视图层进行交互。
onHide() 页面隐藏/切入后台时触发。
onUnload() 页面卸载时触发。
和小程序实例的生命周期对比,其实页面也是有些相似。这里需要注意几点:
- 当前页面路径的参数获取,只能在
onLoad(query)的query参数中获取,无法在onShow()中获取 onLoad、onReady和onUnload,一个页面都只会调用一次- 页面是卸载还是切换到后台,这些除了与小程序的后台切换有关系,还会与页面的跳转、切换逻辑有关系
# 页面导航
# 获取页面栈
在小程序中所有页面的路由全部由框架进行管理,框架以栈的形式维护了当前的所有页面。小程序中页面栈最多十层,也就是十个 WebView,如果超过了十个之后,就没法再打开新的页面了。
对于每一个新的页面层级,渲染层都需要进行一些额外的准备工作。在小程序启动前,客户端会提前准备好一个页面层级用于展示小程序的首页。除此以外,每当一个页面层级被用于渲染页面,客户端都会提前开始准备一个新的页面层级,使得每次调用wx.navigateTo都能够尽快展示一个新的页面。
getCurrentPages()函数用于获取当前页面栈的实例,以数组形式按栈的顺序给出,第一个元素为首页,最后一个元素为当前页面。 需要注意的是:
- 修改页面栈会导致路由以及页面状态错误
App.onLaunch的时候 page 还没有生成,不能在这调用getCurrentPages()
但是其实不是每一次切换页面,都会被记录到页面栈里,我们看看页面导航的一些方法和行为:
| 路由方式 | 触发时机 | 页面栈表现 | 进入方式 |
|---|---|---|---|
| 初始化 | 小程序打开的第一个页面 | 新页面入栈 | 从下往上升起 |
| 打开新页面 | 调用 API wx.navigateTo | 新页面入栈 | 从右往左切入 |
| 页面重定向 | 调用 API wx.redirectTo | 当前页面出栈,新页面入栈 | 页面重新加载 |
| 页面返回 | 返回/调用 API wx.navigateBack | 页面不断出栈,直到目标返回页 | 从右往左切回 |
| Tab 切换 | 切换/调用 API wx.switchTab | 页面全部出栈,只留下新的 Tab 页面 | 页面重新加载 |
| 重加载 | 调用 API wx.reLaunch | 页面全部出栈,只留下新的页面 | 页面重新加载 |
关于导航 API 的几个补充点:
wx.navigateTo和wx.redirectTo只能打开非 TabBar 页面,wx.switchTab只能打开 Tabbar 页面,wx.reLaunch可以打开任意页面- TabBar 页面指在 app.json 的 TabBar 字段定义的页面(客户端窗口的底部或顶部有 tab 栏可以切换页面)
- 跳转到 TabBar 页面,路径后不能带参数(注意,Tabbar 页面初始化之后不会被销毁)
- 调用页面路由带的参数可以在目标页面的
onLoad中获取
# 页面层级关系
一个小程序会拥有多个页面。在小程序里会有页面的层级关系,例如通过wx.navigateTo推入一个新的页面,在首页使用 2 次wx.navigateTo后,页面层级会有三层,我们把这样的一个页面层级称为页面栈。
我们知道页面栈的表现,以及一些常见的导航方法,而小程序基础库也在页面层级做了些体验优化。
对于每一个新的页面层级,视图层都需要进行一些额外的准备工作:
- 在小程序启动前,微信会提前准备好一个页面层级用于展示小程序的首页
- 每当一个页面层级被用于渲染页面,微信都会提前开始准备一个新的页面层级,减少每次新开页面的耗时
每个页面的准备都有三个阶段:
- 启动一个 WebView。
- WebView 中初始化基础库(此时还会进行一些基础库内部优化,以提升页面渲染性能)。
- 注入小程序 WXML 结构和 WXSS 样式(小程序能在接收到页面初始数据之后马上开始渲染页面)。
注意:wx.redirectTo不会打开一个新的页面层级,而是将当前页面层级重新初始化。
# 页面跳转技巧
小程序的 JS 脚本是运行在 JsCore 的线程里,小程序的每个页面各自有一个 WebView 线程进行渲染,所以小程序切换页面时,小程序逻辑层的 JS 脚本运行上下文依旧在同一个 JsCore 线程中。因为在同一个 JsCore 线程中,我们就会有一些问题会遇到,也可以有一些小技巧来处理。
# 判断跳转来源
由于切换页面后,业务逻辑依然在同一个 JsCore 线程中。因此,即使是小程序页面被关闭 unload 之后,如果有原本在执行的逻辑,会继续执行完毕。
在这样的情况下,如果有重定向、跳转等逻辑,在跳转之后后续的逻辑依然会继续执行,这时候如果还有其他的跳转逻辑,可能会导致页面连续跳转,严重的话跳转参数丢书会导致白屏。
为了防止用户自行返回等操作,可以添加当前页面的条件判断是否要执行,页面栈可以通过getCurrentPages拿到,例如我们可以添加这样的方法处理:
// 处理是否有当前路由
function matchOriginPath(originPageUrl) {
let currentPages = getCurrentPages();
const currentPage = currentPages[currentPages.length - 1].route;
// 判断是否设置了特定页面才进行跳转
// 如果设置了,判断当前页面是否特定页面,是才跳转
// 用于判断当前页面是否已经被跳转走(用户手动关闭等)
const isMatch = !originPageUrl || (originPageUrl && currentPage.indexOf(originPageUrl) > -1);
// 如果设置了,当页面路径不匹配,则进行报错提示
if (!isMatch) {
console.error(
"matchOriginPath do not match",
`currentPage: ${currentPage}, originPageUrl: ${originPageUrl}`
);
}
return isMatch;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
通过这样的检查方式,我们可以通过传参来判断下是否要检查:
/**
* 跳转到页面
* @param {object} url 要跳转的页面地址
* @param {object} originPageUrl 原始页面地址,用于判断来源是否符合
*/
export function navigateTo(url: string, originPageUrl?: string) {
// 不符合源页面条件则不跳转
if (!matchOriginPath(originPageUrl!)) {
logger.RUN("navigateTo", "originPageUrl != currentPage, return");
return Promise.resolve();
}
console.log(url);
wx.navigateTo({ url });
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这样,我们跳转的时候可以添加参数,预防页面非预期的跳转:
navigateTo({url: '/pages/pageB'}, '/pages/pageA');
// 后面的逻辑在页面跳转之后,不会再生效
navigateTo({url: '/pages/pageC'}, '/pages/pageA');
2
3
# 跳转传参
小程序提供的跳转相关 API,需要在 url 后面添加参数的方式来传参,但有些时候我们不仅仅需要携带简单的字符串或者数字,我们还可能需要携带一个较大的对象数据。那么这种情况下,由于小程序页面切换依然在同一个 JsCore 上下文,我们可以通过共享对象的方式来传递。
共享对象需要在公共库中存储一个当前跳转的传参内容,同时为了避免页面同时跳转导致传参内容不匹配,我们可以通过一个随机 ID 的方式来标记:
export function getRandomId() {
// 时间戳(9位) + 随机串(10位)
return (Date.now()).toString(32) + Math.random().toString(32).substring(2);
}
2
3
4
跳转的时候,我们可以根据 url 传参的方式,还是共享对象传参的方式,来进行不同的判断处理:
let globalPageParams = undefined; // 全局页面跳转参数
let globalPageParamsId: any = undefined; // 全局页面跳转参数Id,用于标识某一次跳转的数据
// 跳转时参数处理
function mangeUrl(url, options) {
const { urlParams, pageParams } = options;
// url参数处理
if (urlParams) {
url = addUrlParams(url, urlParams);
}
// 页面参数处理
if (pageParams) {
globalPageParams = objectCopy(pageParams);
// 获取随机 ID
globalPageParamsId = getRandomId();
// 将随机 ID 带入 url 参数中,可用来获取全局参数
url = addUrlParams(url, { randomid: globalPageParamsId });
} else {
globalPageParams = undefined;
globalPageParamsId = undefined;
}
return url;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这样,我们的跳转方法可以这么处理:
/**
* 跳转到页面
* @param {object} url 要跳转的页面地址
* @param {object} options 要携带的参数信息
* @param {object} originPageUrl 原始页面地址,用于判断来源是否符合
*/
export function navigateTo(url, options = {}, originPageUrl) {
url = mangeUrl(url, options);
// 不符合源页面条件则不跳转
if (!matchOriginPath(originPageUrl!)) {
logger.RUN("navigateTo", "originPageUrl != currentPage, return");
return Promise.resolve();
}
wx.navigateTo({ url });
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 结合 Component 自动取参
结合 Component 自动取参有几个好处:
- 可以通过 Behavior 来拓展组件的通用能力。
- 可以直接通过定义 properties 来获取页面参数。
页面如何使用 Behavior 看看官方文档 (opens new window) (opens new window):事实上,小程序的页面也可以视为自定义组件。因而,页面也可以使用
Component构造器构造,拥有与普通组件一样的定义段与实例方法。但此时要求对应json文件中包含usingComponents定义段。
这里配合跳转传参,我们可以省略很多的逻辑。例如我们有一个结果页面,页面展示直接从 url 中取值(如果使用 Page 的 query 方式获取参数,需要自己进行 decodeURIComponent 才能使用,而使用组件的 properties 则不需要):
Component({
// 其他配置省略
properties: {
type: String, // 结果类型,成功-success,失败-warn
title: String, // 主要文案
info: String // 辅助文案
}
});
2
3
4
5
6
7
8
我们这样进行跳转:
navigateTo("/pages/result/result", {
// 直接带入参数,result组件可通过properties直接拿到
urlParams: {
type: "success",
title: "操作成功",
info: "成功就是这么简单"
}
});
2
3
4
5
6
7
8
则可以直接在模板中显示:
<!-- 使用的 weui 组件库 -->
<view class="page">
<weui-msg type="{{type}}" title="{{title}}">
<view slot="desc">{{info}}</view>
</weui-msg>
</view>
2
3
4
5
6
如果是通过页面传参的方式,则需要通过随机 ID 来获取对应的参数:
// 通过随机 ID 获取对应参数
export function getPageParams(randomId) {
if (globalPageParamsId === randomId) {
return globalPageParams || {};
}
return {};
}
2
3
4
5
6
7
组件中可以通过 properties 来获取随机 ID,然后获取对应参数:
Component({
// 其他配置省略
properties: {
randomid: String, // 随机 ID
},
methods: {
onLoad() {
// 获取参数
const params = getPageParams(this.data.randomid);
// 处理参数
}
}
});
2
3
4
5
6
7
8
9
10
11
12
13