# 编排引擎
如何从零开始设计编排模块,设计思路是什么? 思考编排的本质是什么? 如何围绕着本质设计并实现对应的功能模块。
# 简介
所谓编排,即将设计器中的所有物料,进行布局设置、组件设置、交互设置(JS 编写/逻辑编排)后, 形成符合业务诉求的 schema 描述。 编排的本质是生产符合《低代码引擎搭建协议规范》的数据,在这个场景里,协议是通过 JSON 来承载的 。专注于 Schema 可视化编排,以可视化的交互方式提供页面结构编排服务。
在真实场景,节点数可能有成百上千,每个节点都具有新增、删除、修改、移动、插入子节点等 操作,同时还有若干约束,JSON 结构操作起来不是很便利,于是我们仿 DOM 设计了节点模型 & 属性模型,用更具可编程性的方式来编排,这是编排系统的基石。
那么编排的本质是什么?
是产生符合搭建协议 (opens new window)**的数据结构,**讲直白点,就是构造一个 JSON 数据结构,直接修改这个 JSON 数据结构,即可完成编排!schema to schema。JSON 结构操作起来不是很便利,于是我们仿 DOM 设计了 节点模型 & 属性模型,用更具可编程性的方式来编排,这是编排系统的基石。
其次,每次编排动作后(CRUD),都需要实时的渲染出视图。广义的视图应该包括各种平台上的展现,浏览器、Rax、小程序、Flutter 等等,所以使用何种渲染器去渲染 JSON 结构应该可以由用户去扩展,我们定义一种机制去衔接设计态和渲染态。 除此之外,还有诸如以下许多模块,这些功能的目的都是辅助用户在画布上有更好的编排体验、扩展能力而逐个增加设计的。
- 编排面板的整体功能区划分设计
- 节点属性设计;节点删除、移动等操作设计,容器节点设计
- 节点拖拽功能、拖拽定位设计和实现
- 节点在画布上的辅助功能,比如 hover、选中、选中时的操作项、resize、拖拽占位符等
- 设计态和渲染态的坐标系转换,滚动监听等
- 快捷键机制
- 历史功能,撤销和重做
- 结构化的插件扩展机制
- 原地编辑功能
# 整体架构
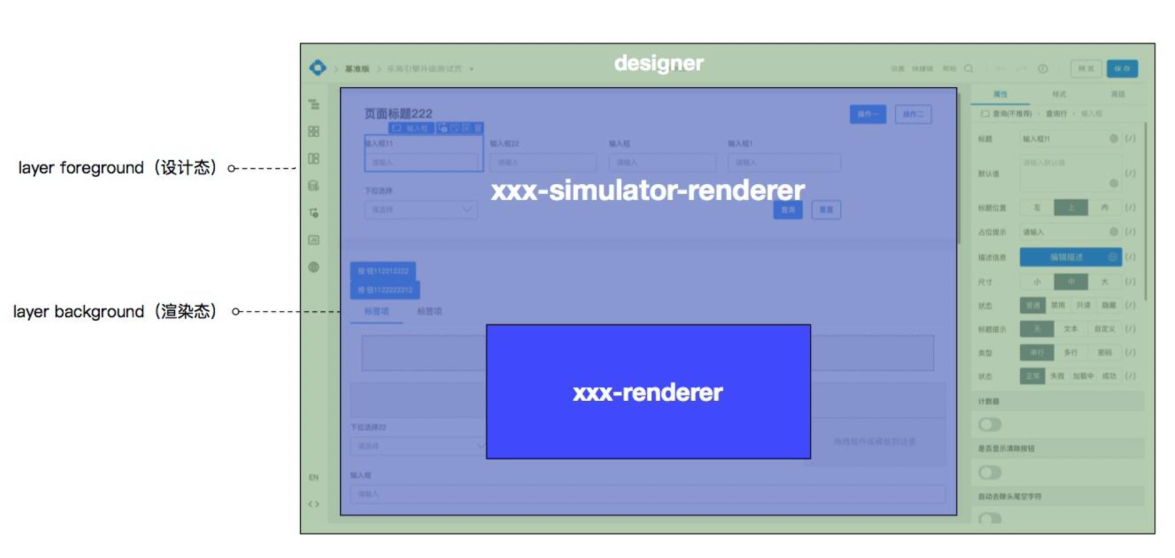
架构说明与解析(重点):
编排引擎完成的是将输入的物料、SCHEMA,经过用户的编排操作产出新的 SCHEMA 的过程(schema to schema)。因此,整个流程的起点是物料的接入和 SCHEMA 的加载 ①,终点则是描述管理器 ④ 导出新的 SCHEMA。流程内会经过引擎工作区的编排 ② 和 碰撞算法检测 ③。
在整个流程的最开始准备阶段物料 ① 会经过装饰器装饰,为其增加生命周期函数,就能在物料编排过程的各个生命周期中处理特殊的业务逻辑,例如:下拉菜单的 Menu 渲染之后可以添加子节点 Menu.Item,也会为增加拖拽能力,使物料变成可拖拽物料,同时监听物料的各种编排事件(例如 drag、dropOver、dropEnd、hover 等),从而进行编排逻辑处理。
在准备阶段之后,用户就可以在引擎工作区 ② 进行页面搭建,你可以进行如下操作:
- 实体区块:用于展示页面搭建的物料、模型的列表,用户可以将其拖拽到画布区块中;
- 画布区块:用于页面编排的操作面板,对用户的编排行为进行响应,实时刷新画布面板;
- 操作区块:用于对页面、区块、模型的描述、变量、函数、事件的自定义的修改和展示;
- 属性面板:用于物料、区块、模型的属性编辑、事件绑定、数据绑定的操作面板;
- 大纲面板:用于页面大纲树展示的面板,方便用户查看页面结构,快速选定所需要的节点;
- 代码面板:用于页面全局函数,以及页面生命周期函数的业务定制开发。
上面所有的区块和面板在引擎内都内置一个相对简单的实现,然而上层的业务搭建中台业务复杂,各个模块的自定义程度高,例如:自定义的实体区块、自定义的画布事件、自定义的操作区域等,这些业务拓展点在引擎中都需要被支持的,引擎整体设计遵循开放封闭原则,封装变化,降低耦合,采用 Event Bus 的机制和核心能力输出方式满足高级的业务拓展要求,将引擎内操作事件广播出去,供第三方使用,同时提供核心能力,如 数据拖拽能力、操作 Schema 能力、Schema 导入/导出能力、历史版本管理能(回滚)力。
用户在引擎工作区进行页面搭建时,对于流式布局的拖拽方案,一定程度会限制用户的布局能力,以保证生成代码的可读性和可用性,引擎需要根据用户操作节点的位置坐标,进行碰撞算法检测 ③,根据用户拖拽的意图,计算出用户操作的节点应正确插入到 Schema 的哪个位置。
最后,用户在引擎工作区上所有编排操作,最终都会通过描述管理器 ④ SchemaManager 类(封装了对 Schema 的常见操作)统一处理,转换成对 Schema 的修改,从而完成引擎的最后流程。
# 总体设计原则
- 编排模块针对单个或多个页面、区块级编辑,可独立使用
- 编排模块在一个页面可多个同时使用,互不影响,状态互相隔离,但一般在编辑器框架中只使用一个
- 其中模拟器基于渲染器封装,渲染模块可被替换
- 输入输出符合《低代码搭建基础协议规范》的 Schema JSON
- 模型抽象与视图表现层分离设计
# 编排实例设计
- 内容的存取
- 选区的读取及控制
- 历史操作记录的访问控制
- 拖拽发起
- 新增拖拽投入区域:比如大纲树的拖拽
- 节点 CRUD
- 新增节点内容
- 事件反馈
- 对以下字段进行编辑
# 选取操作
- 选中节点:选中一个或多个节点
- 取消选中
- 获取当前选中的节点
- 选区发生变化
- 内容变化时调整选中项
# 历史操作记录
- 撤销、重做
- 设置保存点
- 是否在保存点:判断是否编辑
- 状态变化通知
- 获取状态:是否可撤销、是否可重做、是否在保存点
- 可设置记录阀门,短时间多次编辑记录到一个点
# 模型设计
编排实际上操作 schema,但是实际代码运行的过程中,我们将 schema 分成了很多层,每一层有各自的职责,他们所负责的功能是明确清晰的。这就是低代码引擎中的模型设计。通过将 schema 和常用的操作等结合起来,最终将低代码引擎的模型分为节点模型、属性模型、 文档模型和项目模型。
# 项目模型 - Project
项目模型提供项目管理能力。通常一个引擎启动会默认创建一个 Project 实例,有且只有一个。项目模型实例下可以持有多个文档模型的实例,而当前处于设计器设计状态的文档模型,我们将其添加 active 标识,也将其称为 currentDocument,可以通过 project.currentDocument 获得。
一个 Project 包含若干个 DocumentModel 实例,即项目模型和文档模型的关系是 1 对 n
interface Project {
documents: DocumentContext[];
displayMode: 'single' | 'split'; // P2
getDocument(id: string): DocumentContext;
addDocument(data: DocumentSchema): DocumentContext;
getProjectSchema(): ProjectSchema;
setProjectSchema(schema: ProjectSchema): void;
/**
* 分字段设置储存数据
*/
set(key: 'componentsTree' | 'componentsMap' | 'utils' | 'constants' | 'i18n' | 'css' | 'dataSource' | string, any): void;
/**
* 分字段设置储存数据
*/
get(key: 'componentsTree' | 'componentsMap' | 'utils' | 'constants' | 'i18n' | 'css' | 'dataSource' | string): any;
/**
* document 发生变化
*/
onCurrentDocumentChange(func: (document: DocumentModel) => void): () => void;
/**
* 画布渲染器 ready
*/
onRendererReady(func: (renderer: ISimulatorRenderer) => void): () => void;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 文档模型 - DocumentModel
文档模型提供文档管理的能力,每一个页面即一个文档流,对应一个文档模型。文档模型包含了一组 Node 组成的一颗树,类似于 DOM。我们可以通过文档模型来操作 Node 树,来达到管理文档模型的能力。每一个文档模型对应多个 Node,但是根 Node 只有一个,即 rootNode 和 nodes。
文档模型可以通过 Node 树,通过 doc.schema 来导出文档的 schema,并使用其进行渲染。
interface DocumentModel {
/**
* 选区控制
*/
selection: Selection;
/**
* 操作记录控制
*/
history: History;
/**
* 模拟器
*/
simulator?: ISimulatorHost;
/**
* 是否已修改
*/
isModified(): boolean;
/**
* 根节点 类型有:Page/Component/Block
*/
getRootNode(): RootNode;
/**
* 获取节点
*/
getNode(id: string): Node;
/**
* 根据 schema 创建一个节点
*/
createNode(data: NodeSchema): Node;
/**
* 插入一个节点
*/
insertNode(parent: Node, thing: Node | Schema, at?: number | null, copy?: boolean): Node;
/**
* 移除一个节点
*/
removeNode(idOrNode: string | INode): void;
/**
* 生成唯一id
*/
nextId(): string;
/**
* 导出 schema 数据
*/
getSchema(): Schema;
/**
* 导出节点 Schema
*/
getNodeSchema(id: string): Schema;
/**
* 根据节点取得视图实例,在循环等场景会有多个,依赖 simulator 的接口
*/
getView(node: Node): ViewInstance[] | null;
/**
* 通过 DOM 节点获取节点,依赖 simulator 的接口
*/
getNodeFromElement(target: Element | null): Node | null;
/**
* 获得到的结果是一个数组
* 表示一个实例对应多个外层 DOM 节点,依赖 simulator 的接口
*/
getDOMNodes(viewInstance: ViewInstance): Array<Element | Text> | null;
/**
* 激活当前文档
*/
active(): void;
/**
* 不激活
*/
suspense(): void;
/**
* 销毁
*/
destroy(): void;
// ===== 事件集合 =====
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# 节点模型 - Node
Node 节点模型功能聚焦于单层级的 schema 相关操作 。Node 节点模型核心功能点有三个:
Props管理:通过Props实例管理所有的Prop,包括新增、设置、删除等Prop相关操作。Node管理:管理Node树的关系,修改当前Node节点或者Node子节点等。Schema管理:可以通过Node获取当前层级的Schema描述协议内容,并且也可以修改它。
通过 Node 这一层级,对 Props、Node 树和 Schema 的管理粒度控制到最低,这样扩展性也就更强。
# 属性模型 - Prop
一个 Props 对应多个 Prop,每一个 Prop 对应 schema 的 props 下的一个字段。
Props 管理的是 Node 节点模型中的 props 字段下的内容。而 Prop 管理的是 props 下的每一个 key 的内容,例如下面的示例中,一个 Props 管理至少 6 个 Prop,而其中一个 Prop 管理的是 showTitle 的结果。
# 组件描述模型 - ComponentMeta
编排已经等价于直接操作节点 & 属性了,而一个节点和一组对应的属性相当于一个真实的组件,而真实的组件一定是有约束的,比如组件名、组件类型、支持哪些属性以及属性类型、组件能否拖动、支持哪些扩展操作、组件是否是容器型组件、A 组件中能否放入 B 组件等等。
于是,我们设计了一份协议专门负责组件描述,即《中后台搭建组件描述协议》,而编排模块中也有负责解析和使用符合描述协议规范的模块。
每一个组件对应一个 ComponentMeta 的实例,其属性和方法就是描述协议中的所有字段,所有 ComponentMeta 都由设计器器的 designer 模块进行创建和管理,其他模块通过 designer 来获取指定的 ComponentMeta 实例,尤其是每个 Node 实例上都会挂载对应的 ComponentMeta 实例。组件描述模型是后续编排辅助的基础,包括设置面板、拖拽定位机制等。ComponentMeta 就是低代码物料开发时要做的配置。
# 项目、文档、节点和属性模型关系
整体来看,一个 Project 包含若干个 DocumentModel 实例,每个 DocumentModel 包含一组 Node 构成一颗树(类似 DOM 树),每个 Node 通过 Props 实例管理所有 Prop。整体的关系图如下。节点 & 属性模型等价于 JSON 数据结构,而编排的本质是产出 JSON 数据结构,现在可以重新表述为编排的本质是操作节点 & 属性模型了。
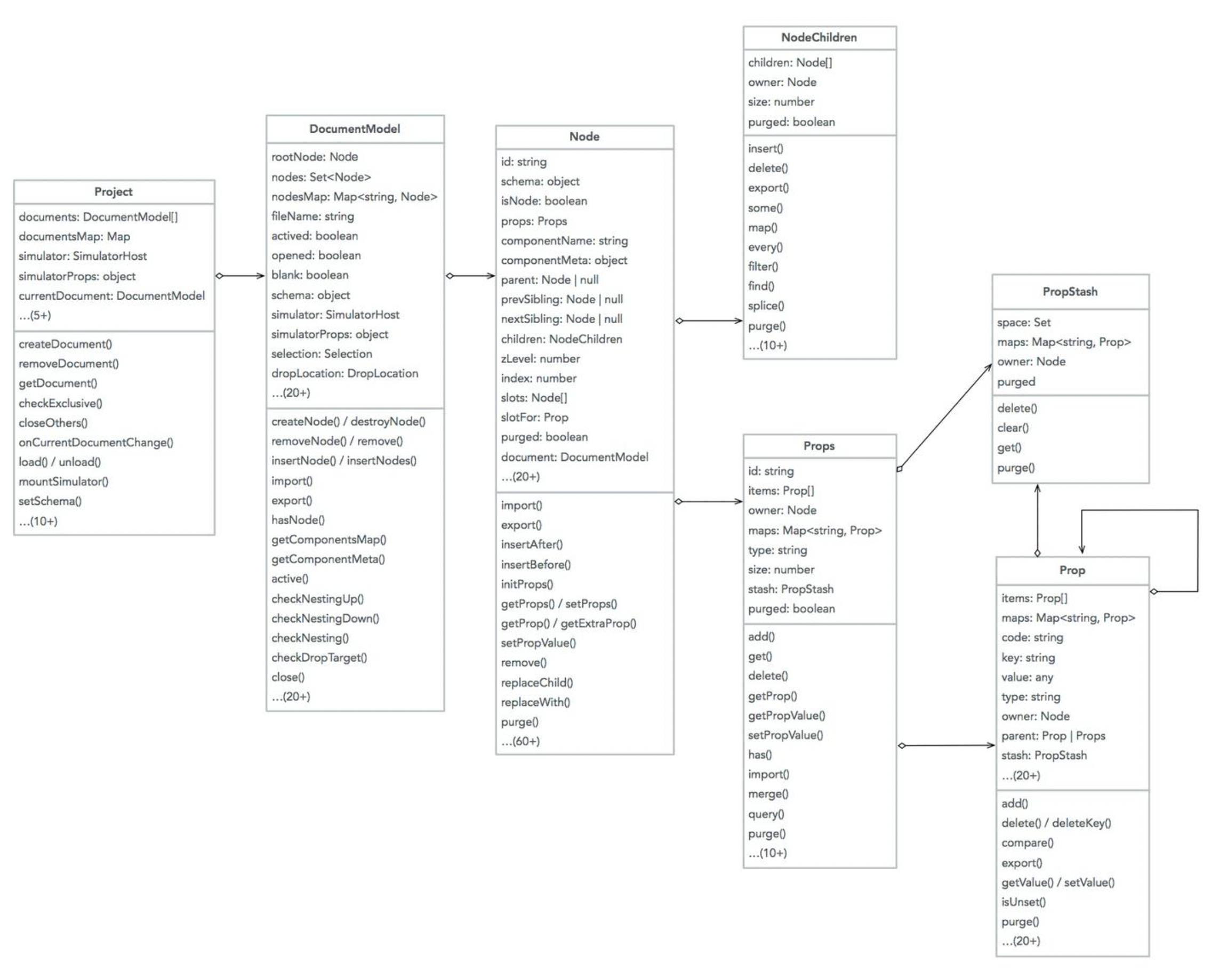
一个 Project 包含若干个 DocumentModel 实例,每个 DocumentModel 包含一组 Node 构成一颗树(类似 DOM),节点树的根节点的 componentName 只能是 Page / Component / Block 之一,每个 Node 通过 Props 实例管理所有 Prop。特别说明几点:
- Prop 是递归实现的,也就是说底层 Props 也是一颗属性树;
- 每个插槽也是一个 Node 实例,关联到所属宿主 Node 的相应 Prop 上;
- Node / Prop 在编排过程中,会被频繁操作,一定要注意 Node / Prop 的创建和销毁逻辑的处理,否则会出现 Node / Prop 数越来越多导致内存泄漏;
- PropStash 用于获取时(get/query)临时生成 Prop,区别于原本就存在的 Prop,后续会写入到相应位置;
节点 & 属性模型等价于 JSON 数据结构,而编排的本质是产出 JSON 数据结构,现在可以重新表述为编排的本质是操作节点 & 属性模型了。
// 一段编排的示例代码
rootNode.insertAfter({ componentName: 'Button', props: { size: 'medium' } });
rootNode.insertAfter({ componentName: 'Button', props: { size: 'medium' } });
rootNode.children.get(1).getProp('size').setValue('large');
rootNode.children.get(2).remove();
rootNode.export(); // => 产出 schema
2
3
4
5
6
7
# 画布渲染设计
采用设计态和渲染态的双层架构
设计器和渲染器其实处在不同的 Frame 下,渲染器以单独的 iframe 嵌入。这样做的好处,一是为了给渲染器一个更纯净的运行环境,更贴近生产环境,二是扩展性考虑,让用户基于接口约束自定义自己的渲染器。
那么,xxx-simulator-renderer 和 xxx-renderer 作用分别是什么?两者之间有何关系?
- xxx-renderer 是一个纯 renderer,即一个渲染器,通过给定输入 schema、依赖组件和配置参数(device / locale 等)之后完成渲染。
- xxx-simulator-renderer 通过和 host 进行通信来和设计器打交道,提供了 DocumentModel 获取 schema 和组件,提供的是将设计器传入的 DocumentModel 和组件/库描述转成相应的 schema 和 组件类(实现响应式,后面再介绍),最后将其传入 xxx-renderer 来完成渲染。另外其提供了一些必要的接口,来帮助设计器完成交互,比如点击渲染画布任意一个位置,需要能计算出点击的组件实例,继而找到设计器对应的 Node 实例,以及组件实例的位置/尺寸信息(DOMRect),让设计器完成辅助 UI 的绘制,如节点选中。
# 通信机制
既然设计器和渲染器处于两个 Frame,它们之间的事件通信、方法调用是通过各自的代理对象进行的,不允许其他方式,避免代码耦合。
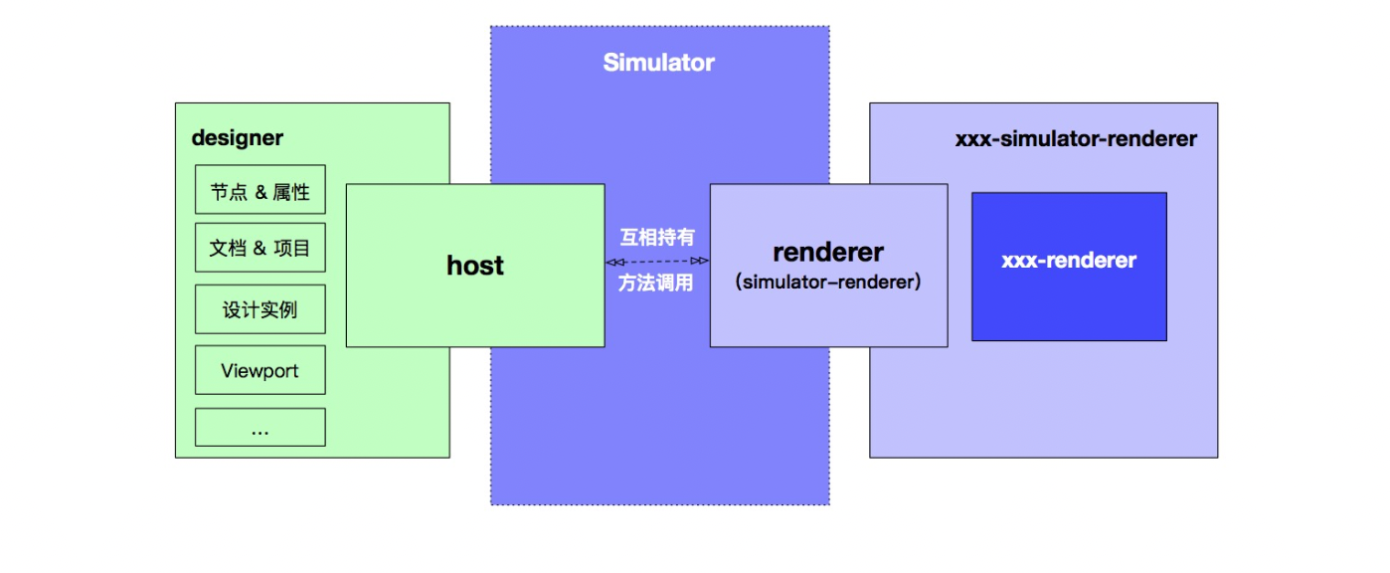
# host
host 可以访问设计器的所有模块,由于 renderer 层不负责与设计器相关的交互。所以增加了一层 host,作为通信的中间层。host 可以访问到设计器中所有模块,并提供相关方法供 simulator-renderer 层调用。例如 schema 的获取、组件获取等。
simulator-renderer 通过调用 host 的方法,将 schema、components 等参数传给 renderer,让 renderer 进行渲染。
# xxx-simulator-renderer
为了完成双向交互,simulator-renderer 也需要提供一些方法来供 host 层调用,之后当设计器和用户有交互,例如上述提到的节点选中。这里需要提供的方法有:
- getClientRects
- getClosestNodeInstance
- findDOMNodes
- getComponent
- setNativeSelection
- setDraggingState
- setCopyState
- clearState
这样,host 和 simulator-renderer 之间便通过相关方法实现了双向通信,能在隔离设计器的基础上完成设计器到画布和画布到设计器的通信流程。
# simulator 机制(simulatorHost 通信机制)
既然设计器和渲染器处于两个 Frame,它们之间的事件通信、方法调用是通过各自的代理对象进行的,不允许其他方式,避免代码耦合。host 理论上可以访问到设计器中所有模块,但目前 renderer 只会调用 host 的 schema 生成、组件类获取以及若干配置属性。host 和 renderer 构成了引擎的 simulator 机制,所以内部 host 写作 simulatorHost,renderer 写作 simulatorRenderer。
# simulatorRenderer(渲染加载机制)
simulatorHost 中将资源分成 4 类,分别是 Environment / Library / Theme / Runtime,每种类型都支持 url & text。将 4 类资源在 createSimulator 时写入,待到 contentWindow onload 后完成 simulatorRenderer 的初始化。