# V18 - Automatic Batching
在 React State 章节介绍了在 legacy 模式下的 state 更新流程,这种模式下的批量更新原理本质上是通过不同的更新上下文开关 Context ,比如 batch 或者 event 来让更新变成可控的。那么在 v18 concurrent 下 React 的更新又有哪些特点呢?
在了解 v18 concurrent 之前,先来看一下主流框架中两种批量更新的原理:
- 微任务、宏任务实现集中更新
- 可控任务实现批量更新
# 批量更新
# 微任务、宏任务实现集中更新
试想一下,比如每次更新,我们先并不去立即执行更新任务,而是先把每一个更新任务放入一个待更新队列 updateQueue 里面,然后 js 执行完毕,用一个微任务统一去批量更新队列里面的任务,如果微任务存在兼容性,那么降级成一个宏任务。这里优先采用微任务的原因就是微任务的执行时机要早于下一次宏任务的执行。
这种在微任务、宏任务实现集中更新典型的案例就是 vue 更新原理,vue.$nextTick原理 ,还有接下来要介绍的 v18 中 scheduleMicrotask 的更新原理。
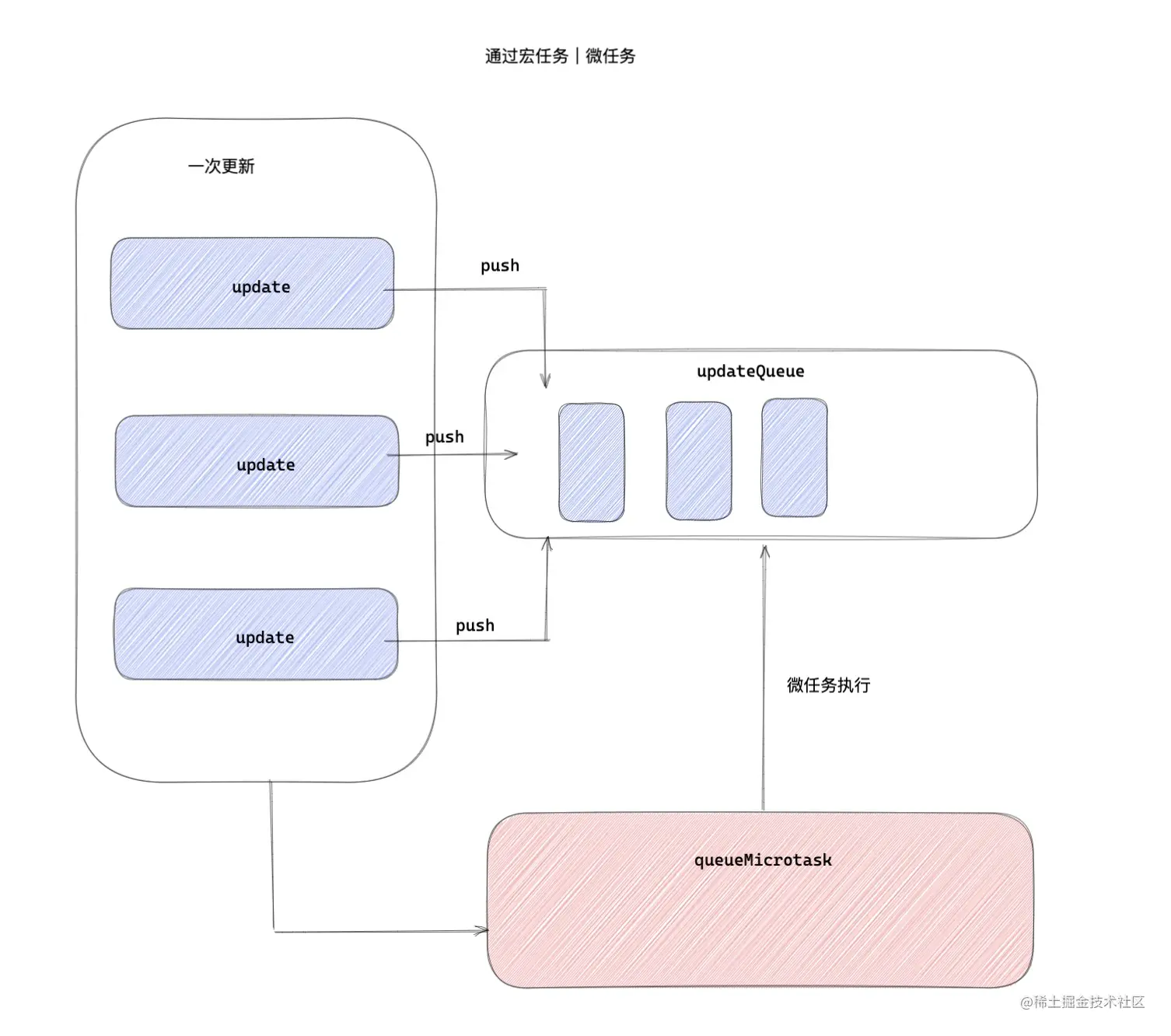
模拟一下整个流程的实现。
class Scheduler {
constructor(){
this.callbacks = []
/* 微任务批量处理 */
queueMicrotask(()=>{
this.runTask()
})
}
/* 增加任务 */
addTask(fn){
this.callbacks.push(fn)
}
runTask(){
console.log('------合并更新开始------')
while(this.callbacks.length > 0){
const cur = this.callbacks.shift()
cur()
}
console.log('------合并更新结束------')
console.log('------开始更新组件------')
}
}
function nextTick(cb){
const scheduler = new Scheduler()
cb(scheduler.addTask.bind(scheduler))
}
/* 模拟一次更新 */
function mockOnclick(){
nextTick((add)=>{
add(function(){
console.log('第一次更新')
})
console.log('----宏任务逻辑----')
add(function(){
console.log('第二次更新')
})
})
}
mockOnclick()
// ----宏任务逻辑---- -> ------合并更新开始------ -> 第一次更新 -> 第二次更新 -> ------合并更新结束------
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
模拟一下具体实现细节:
- 通过一个 Scheduler 调度器来完成整个流程。
- 通过 addTask 每次向队列中放入任务。
- 用 queueMicrotask 创建一个微任务,来统一处理这些任务。
- mockOnclick 模拟一次更新。我们用 nextTick 来模拟一下更新函数的处理逻辑。
# 可控任务实现批量更新
通过拦截把任务变成可控的,典型的就是 React v17 之前的 batchEventUpdate 批量更新,。这种情况的更新来源于对事件进行拦截,比如 React 的事件系统。以 React 的事件批量更新为例子,比如我们的 onClick ,onChange 事件都是被 React 的事件系统处理的。外层用一个统一的处理函数进行拦截。而我们绑定的事件都是在该函数的执行上下文内部被调用的。
那么比如在一次点击事件中触发了多次更新。本质上外层在 React 事件系统处理函数的上下文中,这样的情况下,就可以通过一个开关,证明当前更新是可控的,可以做批量处理。接下来 React 就用一次就可以了。
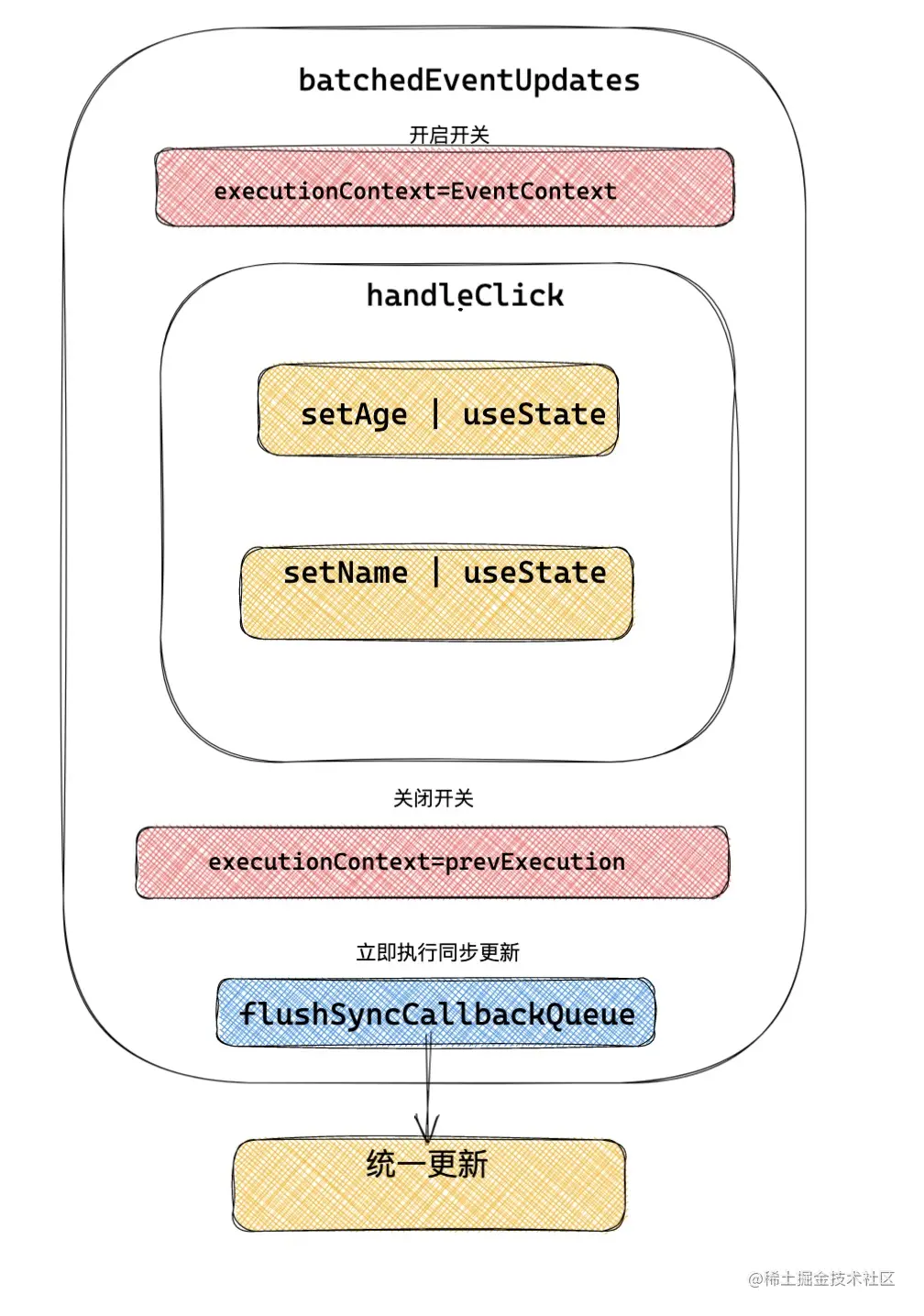
模拟一下具体的实现:
<body>
<button onclick="handleClick()" >点击</button>
</body>
<script>
let batchEventUpdate = false
let callbackQueue = []
function flushSyncCallbackQueue(){
console.log('-----执行批量更新-------')
while(callbackQueue.length > 0 ){
const cur = callbackQueue.shift()
cur()
}
console.log('-----批量更新结束-------')
}
function wrapEvent(fn){
return function (){
/* 开启批量更新状态 */
batchEventUpdate = true
fn()
/* 立即执行更新任务 */
flushSyncCallbackQueue()
/* 关闭批量更新状态 */
batchEventUpdate = false
}
}
function setState(fn){
/* 如果在批量更新状态下,那么批量更新 */
if(batchEventUpdate){
callbackQueue.push(fn)
}else{
/* 如果没有在批量更新条件下,那么直接更新。 */
fn()
}
}
function handleClick(){
setState(()=>{
console.log('---更新1---')
})
console.log('上下文执行')
setState(()=>{
console.log('---更新2---')
})
}
/* 让 handleClick 变成可控的 */
handleClick = wrapEvent(handleClick)
</script>
// 上下文执行 -> -----执行批量更新------- -> ---更新1--- -> ---更新2--- -> -----批量更新结束-------
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
- 本方式的核心就是让 handleClick 通过 wrapEvent 变成可控的。首先 wrapEvent 类似于事件处理函数,在内部通过开关 batchEventUpdate 来判断是否开启批量更新状态,最后通过 flushSyncCallbackQueue 来清空待更新队列。
- 在批量更新条件下,事件会被放入到更新队列中,非批量更新条件下,那么立即执行更新任务。
# 与传统 legacy 模式的区别
首先对于传统的 legacy 模式,有可控任务批量处理的概念,也就是采用了上面第二种批量更新模式:
- 通过不同的更新上下文开关,在开关里的任务是可控的,可以进行批量处理。
- 在事件之行完毕后,通过
flushSyncCallback来进行更新任务之行。
那么在 concurrent 模式下的更新采用了一个什么方式呢?首先在这种模式下,取消了批量更新的感念。我们以事件系统的更新例子,研究一下两种的区别。
// react-dom/src/events/ReactDOMUpdateBatching.js
export function batchedEventUpdates(fn,a){
isBatchingEventUpdates = true; //打开批量更新开关
try{
fn(a) // 事件在这里执行
}finally{
isBatchingEventUpdates = false //关闭批量更新开关
if (executionContext === NoContext) {
flushSyncCallbackQueue(); // TODO: 这个很重要,用来同步执行更新队列中的任务
}
}
}
2
3
4
5
6
7
8
9
10
11
12
- 通过开关
isBatchingEventUpdates来让 fn 里面的更新变成可控的,所以可以进行批量更新。 - 重点就是
flushSyncCallbackQueue用来同步执行更新队列中的任务。
在最新版本的 v18 alpha 系统中,事件变成了这样 :
function batchedEventUpdates(){
var prevExecutionContext = executionContext;
executionContext |= EventContext; // 运算赋值
try {
return fn(a); // 执行函数
}finally {
executionContext = prevExecutionContext; // 重置之前的状态
if (executionContext === NoContext) {
flushSyncCallbacksOnlyInLegacyMode() // 同步执行更新队列中的任务
}
}
}
2
3
4
5
6
7
8
9
10
11
12
从上述代码中可以清晰的看到,v18 alpha 版本的流程大致是这样的:
- 也是通过类似开关状态来控制的,在刚开始的时候将赋值给
EventContext,然后在事件执行之后,赋值给prevExecutionContext。 - 之后同样会触发 flushSyncCallbacksOnlyInLegacyMode ,不过通过函数名称就可以大胆猜想,这个方法主要是针对 legacy 模式的更新,那么 concurrent mode 下也就不会走 flushSyncCallback 的逻辑了。
再看一下 flushSyncCallbacksOnlyInLegacyMode 做了些什么事:
// react-reconciler/src/ReactFiberSyncTaskQueue.js
export function flushSyncCallbacksOnlyInLegacyMode(){
if(includesLegacySyncCallbacks){ /* 只有在 legacy 模式下,才会走这里的流程。 */
flushSyncCallbacks();
}
}
2
3
4
5
6
结论:只有在 legacy 模式下,才会执行 flushSyncCallbacks 来同步执行任务。 flushSyncCallbacks 主要作用是,能够在一次更新中,直接同步更新任务,防止任务在下一次的宏任务中执行。
那么对于 concurrent 下的更新流程是怎么样的呢?一次更新 state 会发生什么?
# 更新原理
在了解更新原理之前,先了解以下 v18 中新增的API ReactDOM.createRoot(),只要使用ReactDOM.createRoot() 方法,就能直接享受自动 batching 的能力。
# createRoot
在 React18 中, ReactDOM.render() 正式成为 Legacy,并增加了新的 API ReactDOM.createRoot() ,他们的用法差别如下:
import ReactDOM from ‘react-dom’;
import App from 'App';
ReactDOM.render(<App />, document.getElementById('root'));
// v18 - createRoot
import ReactDOM from ‘react-dom’;
import App from 'App';
const root = ReactDOM.createRoot(document.getElementById('root'));
root.render(<App />);
2
3
4
5
6
7
8
9
10
11
12
通过新的 API,我们可以为一个 React App 创建多个根节点,甚至在未来可以用不同版本的 React 来创建。React18 保留了上述两种用法,老项目不想改仍然可以用 ReactDOM.render() ;新项目想提升性能,可以用 ReactDOM.createRoot() 且可借并发渲染的好处。
# 什么是 Automatic Batching
为了使应用获得更好的性能,React把多次的状态更新(state updates),合并到一次渲染中。 React17 只会把浏览器事件(如点击)发生期间的状态更新合并掉。而 React18 会把事件处理器发生后的状态更新也合并掉。
batching 是安全的,但也存在一些特殊情况不希望 batching 发生,比如:你需要在状态更新后,立刻读取新 DOM 上的数据等。这种情况下请使用 ReactDOM.flushSync()
import { flushSync } from 'react-dom'; // Note: react-dom, not react
function handleClick() {
flushSync(() => {
setCounter(c => c + 1);
});
// React has updated the DOM by now
flushSync(() => {
setFlag(f => !f);
});
// React has updated the DOM by now
}
2
3
4
5
6
7
8
9
10
11
12
那么 Automatic Batching 对 Hooks/Classes 有什么影响呢?
- 对 Hooks 没有任何影响
- 对 classes 大部分情况下没影响,关注一种模式:是否在两次 setState 之间读取了state 值。差异如下:
handleClick = () => {
setTimeout(() => {
this.setState(({ count }) => ({ count: count + 1 }));
// 在 React17 及之前,打印出来是 { count: 1, flag: false }
// 在 React18,打印出来是 { count: 0, flag: false }
console.log(this.state);
this.setState(({ flag }) => ({ flag: !flag }));
});
};
2
3
4
5
6
7
8
9
10
11
如果不想通过调整代码逻辑的方式进行修正,可以直接采用 ReactDOM.flushSync() :
handleClick = () => {
setTimeout(() => {
ReactDOM.flushSync(() => {
this.setState(({ count }) => ({ count: count + 1 }));
});
// 在 React18,打印出来是 { count: 1, flag: false }
console.log(this.state);
this.setState(({ flag }) => ({ flag: !flag }));
});
};
2
3
4
5
6
7
8
9
10
11
12
# 更新原理
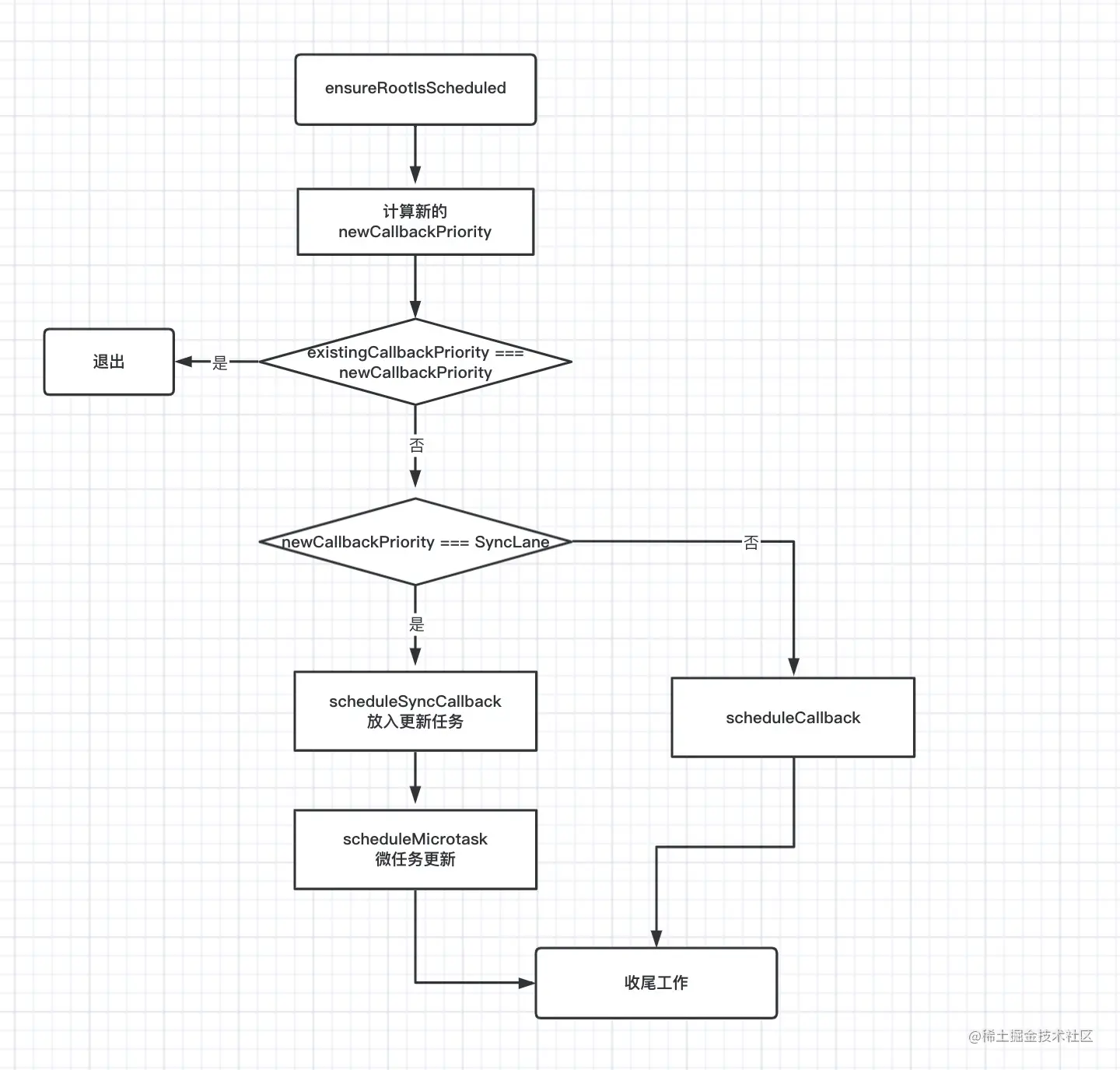
无论是那种条件下,只要触发 React 的 setState 或者 useState,最终进入调度任务开始更新的入口函数都是 ensureRootIsScheduled :
// react-reconciler/src/ReactFiberWorkLoop.js -> ensureRootIsScheduled
function ensureRootIsScheduled(root,currentTime){
var existingCallbackNode = root.callbackNode;
var newCallbackPriority = getHighestPriorityLane(nextLanes);
var existingCallbackPriority = root.callbackPriority;
if (existingCallbackPriority === newCallbackPriority &&
!( ReactCurrentActQueue.current !== null && existingCallbackNode !== fakeActCallbackNode)) {
/* 批量更新退出* */
return;
}
/* 同步更新条件下,会走这里的逻辑 */
if (newCallbackPriority === SyncLane) {
scheduleSyncCallback(performSyncWorkOnRoot.bind(null, root));
/* 用微任务去立即执行更新 */
scheduleMicrotask(flushSyncCallbacks);
}else{
newCallbackNode = scheduleCallback(
schedulerPriorityLevel,
performConcurrentWorkOnRoot.bind(null, root),
);
}
/* 这里很重要就是给当前 root 赋予 callbackPriority 和 callbackNode 状态 */
root.callbackPriority = newCallbackPriority;
root.callbackNode = newCallbackNode;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 同步条件下的逻辑
首先我们来看一下,同步更新的逻辑,上面讲到在 concurrent 中已经没有可控任务那一套逻辑。所以核心更新流程如下:
当同步状态下触发多次 useState 的时候:
- 首先第一次进入到
ensureRootIsScheduled,会计算出newCallbackPriority可以理解成执行新的更新任务的优先级。那么和之前的callbackPriority进行对比,如果相等那么退出流程,那么第一次两者肯定是不想等的。 - 同步状态下常规的更新
newCallbackPriority是等于SyncLane的,那么会执行两个函数,scheduleSyncCallback和scheduleMicrotask。
scheduleSyncCallback 会把任务 syncQueue 同步更新队列中。来看一下这个函数:
// react-reconciler/src/ReactFiberSyncTaskQueue.js -> scheduleSyncCallback
export function scheduleSyncCallback(callback: SchedulerCallback) {
if (syncQueue === null) {
syncQueue = [callback];
} else {
syncQueue.push(callback);
}
}
2
3
4
5
6
7
8
注意
接下来就是 concurrent 下更新的区别了。在老版本的 React 是基于事件处理函数执行的 flushSyncCallbacks ,而新版本 React 是通过 scheduleMicrotask 执行的。
我们看一下 scheduleMicrotask 到底是什么?
// react-reconciler/src/ReactFiberHostConfig.js -> scheduleMicrotask
var scheduleMicrotask = typeof queueMicrotask === 'function' ? queueMicrotask : typeof Promise !== 'undefined' ? function (callback) {
return Promise.resolve(null).then(callback).catch(handleErrorInNextTick);
} : scheduleTimeout;
2
3
4
scheduleMicrotask 本质上就是 Promise.resolve ,还有一个 setTimeout 向下兼容的情况。通过 scheduleMicrotask 去进行调度更新。
那么如果发生第二次 useState ,则会出现 existingCallbackPriority === newCallbackPriority 的情况,接下来就会 return 退出更新流程了。
# 异步条件下的逻辑
在异步情况下,比如在 setTimeout 或者是 Promise.resolve 条件下的更新,会走哪些逻辑呢?
- 第一步也会判断
existingCallbackPriority === newCallbackPriority是否相等,相等则退出。 - 第二步则就有点区别了。会直接执行
scheduleCallback,然后得到最新的newCallbackNode,并赋值给 root 。 - 接下来第二次
useState,同样会 return 跳出ensureRootIsScheduled。
看一下 scheduleCallback 做了哪些事。
// react-reconciler/src/ReactFiberWorkLoop.js -> scheduleCallback
function scheduleCallback(priorityLevel, callback) {
var actQueue = ReactCurrentActQueue.current;
if (actQueue !== null) {
actQueue.push(callback);
return fakeActCallbackNode;
} else {
return scheduleCallback(priorityLevel, callback);
}
}
2
3
4
5
6
7
8
9
10
最后用一幅流程图描述一下流程: