# 虚拟 DOM 与 Diff 算法
# 虚拟 DOM
# 什么是虚拟 DOM
Virtual DOM 本质上是 JavaScript 对象,是真实 DOM 的描述,用一个 JS 对象来描述一个 DOM 节点。
Virtual DOM 可以看做一棵模拟 DOM 树的 JavaScript 树,其主要是通过 VNode 实现一个无状态的组件,当组件状态发生更新时,然后触发 Virtual DOM 数据的变化,然后通过 Virtual DOM 和真实 DOM 的比对,再对真实 DOM 更新。可以简单认为 Virtual DOM 是真实 DOM 的缓存。
# 虚拟 DOM 的优缺点
# 优点
- 跨平台与分层设计(主要原因):虚拟 DOM 本质上是 JavaScript 对象,而真实 DOM 与平台强相关,相比之下虚拟 DOM 带来了分层设计、跨平台以及 SSR 等特性。至于 Virtual DOM 比 原生 DOM 谁的性能好,需要 “控制变量法” 才能比较。这是为什么要设计虚拟 DOM 的主要原因。虚拟 DOM 抽象了原本的渲染过程,实现了跨平台的能力,而不仅仅局限于浏览器的 DOM,可以是安卓和 iOS 的原生组件,也可以是小程序,也可以是各种 GUI。
- 以最小的代价更新变化的视图。整棵 DOM 树实现代价太高,能否只更新变化的部分的视图。虚拟 DOM 能通过 patch 准确地转换为真实 DOM,并且方便进行 diff。
- 保证性能下限(次要原因):框架的虚拟 DOM 需要适配任何上层 API 可能产生的操作(分层设计),它的一些 DOM 操作的实现必须是普适的,所以它的性能并不是最优的;但是比起粗暴的 DOM 操作性能要好很多,因此框架的虚拟 DOM 至少可以保证在你不需要手动优化的情况下,依然可以提供还不错的性能,即保证性能的下限。
- 无需手动操作 DOM:操作 DOM 慢,js 运行效率高。我们可以将 DOM 对比(diff 操作)放在 JS 层,提高效率。我们不再需要手动去操作 DOM,只需要写好 View-Model 的代码逻辑,框架会根据虚拟 DOM 和 数据双向绑定,帮我们以可预期的方式更新视图,极大提高我们的开发效率。
- 组件的高度抽象化:Vue.2x 引入 VirtualDOM 把渲染过程抽象化,从而使得组件的抽象能力也得到提升,并且可以适配 DOM 以外的渲染目标。不再依赖 HTML 解析器进行模版解析,可以进行更多的 AOT 工作提高运行时效率:通过模版 AOT 编译,Vue 的运行时体积可以进一步压缩,运行时效率可以进一步提升。Virtual DOM 的优势不在于单次的操作,而是在大量、频繁的数据更新下,能够对视图进行合理、高效的更新。为了实现高效的 DOM 操作,一套高效的虚拟 DOM diff 算法显得很有必要.
# 缺点
- 无法进行极致优化: 虽然虚拟 DOM + 合理的优化,足以应对绝大部分应用的性能需求,但在一些性能要求极高的应用中虚拟 DOM 无法进行针对性的极致优化。
- 虽然 Vue 能够保证触发更新的组件最小化,但在单个组件内部依然需要遍历该组件的整个 Virtual DOM 树。
- 在一些组件整个模版内只有少量动态节点的情况下,这些遍历都是性能的浪费。
- 传统 Virtual DOM 的性能跟模版大小正相关,跟动态节点的数量无关。
# 虚拟 DOM 实现原理
虚拟 DOM 的实现原理主要包括以下 3 部分:
- 用 JavaScript 对象模拟真实 DOM 树,对真实 DOM 进行抽象;
- diff 算法 — 比较两棵虚拟 DOM 树的差异;
- pach 算法(打补丁) — 将两个虚拟 DOM 对象的差异应用到真正的 DOM 树。
# VNode 类
JavaScript 对象模拟真实 DOM 树,对真实 DOM 进行抽象。vue 是通过 createElement 生成 VNode。
虚拟 DOM 就是用 JS 来描述一个真实的 DOM 节点。而在 Vue 中就存在了一个 VNode 类,通过这个类,我们就可以实例化出不同类型的虚拟 DOM 节点。Vue 中 VNode 的类型:
- 注释节点
- 文本节点
- 元素节点
- 组件节点
- 函数式组件节点
- 克隆节点
其实 VNode 的作用是相当大的。我们在视图渲染之前,把写好的 template 模板先编译成 VNode 并缓存下来,等到数据发生变化页面需要重新渲染的时候,我们把数据发生变化后生成的 VNode 与前一次缓存下来的 VNode 进行对比,找出差异,然后有差异的 VNode 对应的真实 DOM 节点就是需要重新渲染的节点,最后根据有差异的 VNode 创建出真实的 DOM 节点再插入到视图中,最终完成一次视图更新。
虚拟 DOM 其实说白了就是以 JS 的计算性能来换取操作真实 DOM 所消耗的性能。当数据发生变化时,我们对比变化前后的虚拟DOM节点,通过DOM-Diff算法计算出需要更新的地方,然后去更新需要更新的视图。
# createElement
creatElement()
- context 表示 VNode 的上下文环境,是 Component 类型
- tag 表示标签,它可以是一个字符串,也可以是一个 Component 类型
- data 表示 VNode 的数据,它是一个 VNodeData 类型
- children 表示当前 VNode 的子节点,它是任意类型的
- normalizationType 表示子节点规范的类型,类型不同规范的方法也就不一样,主要是参考 render 函数是编译生成的还是用户手写的
normalizeChildren 方法调用场景分为下面两种:
- render 函数是用户手写的
- 编译 slot、v-for 的时候会产生嵌套数组
# createComponent
createComponent 生成 VNode 的三个关键流程:
- 构造子类构造函数 Ctor
- installComponentHooks 安装组件钩子函数
- 实例化 vnode
# Patch 打补丁过程
_update 会将新旧两个 VNode 进行 patch 过程,得出两个 VNode 最小差异,然后将这些差异渲染到视图上。
整个 patch 无非就是干三件事:
- 创建节点:新的 VNode 中有而旧的 oldVNode 中没有,就在旧的 oldVNode 中创建。
- 删除节点:新的 VNode 中没有而旧的 oldVNode 中有,就从旧的 oldVNode 中删除。
- 更新节点:新的 VNode 和旧的 oldVNode 中都有,就以新的 VNode 为准,更新旧的 oldVNode。
# 创建节点 createElm
VNode 类可以描述 6 种类型的节点,而实际上只有 3 种类型的节点能够被创建并插入到 DOM 中,它们分别是:元素节点、文本节点、注释节点。
// 源码位置: /src/core/vdom/patch.js
function createElm(vnode, parentElm, refElm) {
const data = vnode.data;
const children = vnode.children;
const tag = vnode.tag;
if (isDef(tag)) {
vnode.elm = nodeOps.createElement(tag, vnode); // 创建元素节点
createChildren(vnode, children, insertedVnodeQueue); // 创建元素节点的子节点
insert(parentElm, vnode.elm, refElm); // 插入到DOM中
} else if (isTrue(vnode.isComment)) {
vnode.elm = nodeOps.createComment(vnode.text); // 创建注释节点
insert(parentElm, vnode.elm, refElm); // 插入到DOM中
} else {
vnode.elm = nodeOps.createTextNode(vnode.text); // 创建文本节点
insert(parentElm, vnode.elm, refElm); // 插入到DOM中
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 删除节点 removeNode
function removeNode(el) {
const parent = nodeOps.parentNode(el); // 获取父节点
if (isDef(parent)) {
nodeOps.removeChild(parent, el); // 调用父节点的removeChild方法
}
}
2
3
4
5
6
# 更新节点 patchVnode
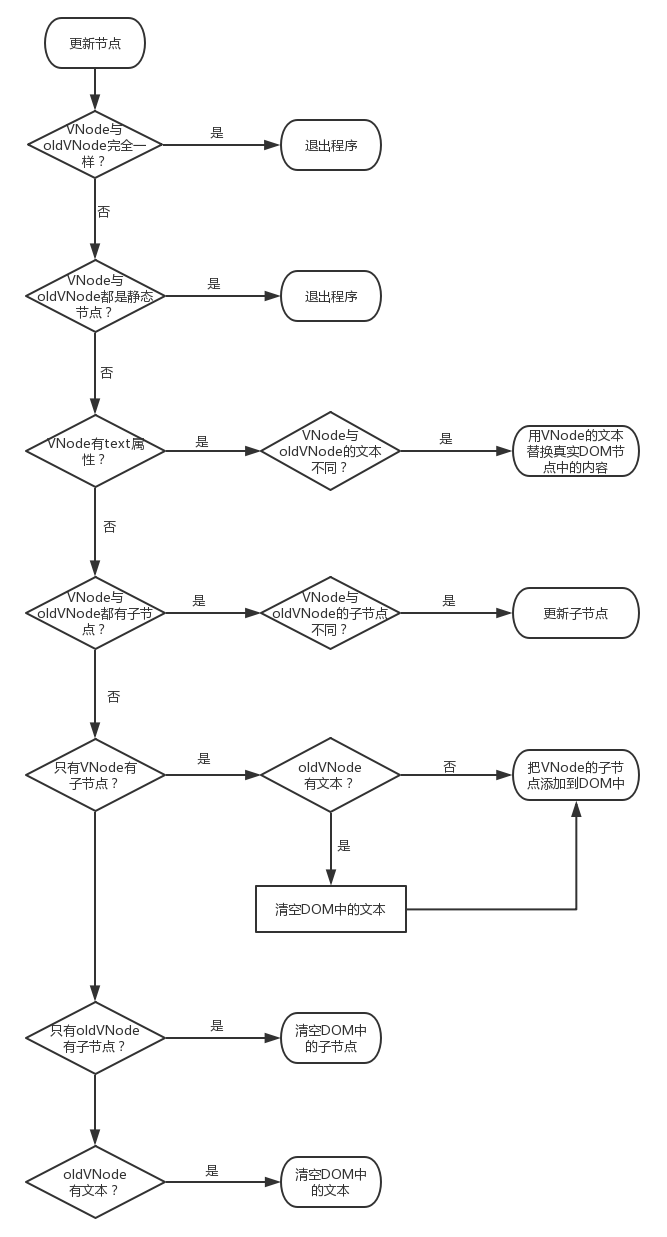
VNode 与 oldVnode 新旧节点相同,不更新,直接结束。
如果新旧 VNode 都是静态(isStatic)的,同时它们的 key 相同(代表同一节点),并且新的 VNode 是 clone 或者是标记了 once(标记 v-once 属性,只渲染一次),那么只需要替换 componentInstance 即可
判断 VNode 是否是文本节点,是否有 text 属性
如果 VNode 不是文本节点,且存在子节点
- 如果 Vnode 和 oldVnode 均有子节点,则执行 updateChildren 对子节点进行 diff 操作,这也是 diff 的核心部分
- 如果 Vnode 有子节点,oldVnode 没有子节点但有文本节点,则将 oldVnode 的文本节点清空,然后插入 Vnode 的子节点;否则直接新增
- 如果 VNode 没有子节点,oldVnode 有子节点,则删除 el 的所有子节点,直接清空
如果 VNode 是文本节点,也就不存在子节点,如果 oldeVnode 和 Vnode 都有文本节点且不相等,那么会将 oldVnode 的文本节点更新为 Vnode 的文本节点
如果 VNode 与 oldVNode 都没有子节点,则清空 oldVnode 的文本节点即可
// 更新节点
function patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly) {
// vnode与oldVnode是否完全一样?若是,退出程序
if (oldVnode === vnode) {
return;
}
const elm = (vnode.elm = oldVnode.elm);
// vnode与oldVnode是否都是静态节点?若是,退出程序
if (
isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
vnode.componentInstance = oldVnode.componentInstance;
return;
}
const oldCh = oldVnode.children;
const ch = vnode.children;
// vnode有text属性?若没有:
if (isUndef(vnode.text)) {
// vnode的子节点与oldVnode的子节点是否都存在?
if (isDef(oldCh) && isDef(ch)) {
// 若都存在,判断子节点是否相同,不同则更新子节点
if (oldCh !== ch)
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly);
}
// 若只有vnode的子节点存在
else if (isDef(ch)) {
/**
* 判断oldVnode是否有文本?
* 若没有,则把vnode的子节点添加到真实DOM中
* 若有,则清空Dom中的文本,再把vnode的子节点添加到真实DOM中
*/
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, "");
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue);
}
// 若只有oldnode的子节点存在
else if (isDef(oldCh)) {
// 清空DOM中的子节点
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
}
// 若vnode和oldnode都没有子节点,但是oldnode中有文本
else if (isDef(oldVnode.text)) {
// 清空oldnode文本
nodeOps.setTextContent(elm, "");
}
// 上面两个判断一句话概括就是,如果vnode中既没有text,也没有子节点,那么对应的oldnode中有什么就清空什么
}
// 若有,vnode的text属性与oldVnode的text属性是否相同?
else if (oldVnode.text !== vnode.text) {
// 若不相同:则用vnode的text替换真实DOM的文本
nodeOps.setTextContent(elm, vnode.text);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
值得注意的是如果新旧 VNode 里都包含了子节点,那么对于子节点的更新在代码里调用了 updateChildren 方法。对于子节点的对比更新会有额外的一些逻辑,即核心的 diff 算法。patch 的核心 diff 算法,只在同层级的 VNode 之间进行比较得到变化,然后修改变化的视图。patch 过程中,如果两个 VNode 被认为是同个 VNode,则会进行深度比较,得出最小差异,否则直接删除旧有 DOM 节点,创建新的 DOM 节点。判断两个 VNode 是否相同是通过 isSameVnode 判断两个虚拟 DOM 节点是否相同,判断依据是两个节点的 key 属性是否一致。
# 核心 Diff 算法
diff 算法是一种通过同层的树节点进行比较的高效算法。diff 整体策略为:深度优先,同层比较
其有两个特点:
- 比较只会在同层级进行, 不会跨层级比较
- 在 diff 比较的过程中,循环从两边向中间比较(vue 的双端比较法)
新旧两个 VNode 节点的左右头尾两侧均有一个变量标识,在遍历过程中这几个变量都会向中间靠拢。当 oldStartIdx <= oldEndIdx 或者 newStartIdx <= newEndIdx 时结束循环。在遍历中,如果存在 key,并且满足 sameVnode,会将该 DOM 节点进行复用(只通过移动节点顺序),否则则会创建一个新的 DOM 节点。
oldStartVnode、oldEndVnode 与 newStartVnode、newEndVnode 两两比较共有四种比较方法:
当新旧子树的两个开始节点或新旧子树的两个结束节点相同时
当新旧 VNode 节点的 start 或者 end 满足 sameVnode 时,也就是 sameVnode(oldStartVnode, newStartVnode) 或者 sameVnode(oldEndVnode, newEndVnode) 表示为 true,直接将该 VNode 节点进行 patchVnode 即可(保留)。
当旧子树的开始节点与新子树的结束节点相同时
当 oldStartVnode 与 newEndVnode 满足 sameVnode,即 sameVnode(oldStartVnode, newEndVnode)。这时候说明 oldStartVnode 已经跑到了 oldEndVnode 后面去了,进行 patchVnode 的同时还需要将真实 DOM 节点移动到 oldEndVnode 的后面。
当旧子树的结束节点与新子树的开始节点相同时
如果 oldEndVnode 与 newStartVnode 满足 sameVnode,即 sameVnode(oldEndVnode, newStartVnode)。这说明 oldEndVnode 跑到了 oldStartVnode 的前面,进行 patchVnode 的同时真实的 DOM 节点移动到了 oldStartVnode 的前面。
当旧子树中没有新子树中的节点,会将新节点插入到 oldStartVnode 前
如果以上情况均不符合,进入 key 的比较:
oldKeyToIdx:一个哈希表,存放旧节点的 key 与节点的映射关系;如果没有 oldKeyToIdx 则会通过 createKeyToOldIdx 会得到一个 oldKeyToIdx,里面存放旧节点的 key 与节点的映射关系,只不过这个 key 是 index 序列。从 oldKeyToIdx 这个哈希表中可以找到与新节点是否有相同 key 的旧节点,如果同时满足 sameVnode,patchVnode 的同时会将这个真实 DOM(elmToMove)移动到 oldStartVnode 对应的真实 DOM 的前面。
idxInOld:拿新节点的 key 去 oldKeyToIdx 找是否有与旧节点相同的节点,即旧节点中是否有与新节点 key 相同的节点,没有就通过 findIdxInOld 遍历旧节点并通过 sameVnode 判断是否有相同节点,有返回索引。
- idxInOld 不存在,即新节点在旧节点中都没有找到,说明这是一个之前没有的新节点,需要通过 createElm 创建新节点
- idxInOld 存在,则进一步通过 sameVnode(vnodeToMove, newStartVnode) 判断是否是同一节点
- 是同一节点,则通过 patchVnode 更新,并移动节点
- 不是同一节点,即相同的 key 不同的元素,则通过 createElm 创建新节点
先 oldStartVnode、oldEndVnode 与 newStartVnode、newEndVnode 两两通过 sameVnode 进行 4 次比较,若成立,则通过 patchVnode 更新节点内容,并移动节点位置。若不成立,再进一步比较 key,idxInOld 判断新节点是否被旧节点复用了。idxInOld 不存在,说明旧节点没有复用新节点,新节点需要 createElm 创建;idxInOld 存在,说明新节点有被复用的可能性,为什么这么说,因为此时我们只知道节点的 key 相同,是否是通过简单的通过移动节点位置达到复用的目的,还是说通过创建节点进行原地复用或就地修改,需要进一步通过 sameVnode(vnodeToMove, newStartVnode) 判断是否是同一节点。是同一节点,则直接通过 patchVnode 更新,并移动节点;否则,虽然有相同的 key 但是不同的元素,则通过 createElm 创建新节点,就地修改。从这一点我们就可以思考出为什么 v-for 的时候要加上 key?为什么这个 key 不建议 index 来标识?
# key 的作用
key 主要用在 Vue 的虚拟 DOM 的 diff 算法中,是 vnode 的唯一标记,diff 算法中双端两两比较一共有 4 种比较方式,如果以上 4 种比较都没匹配,如果设置了 key,就会用 key 再进行比较。通过这个 key,我们的 diff 操作可以更准确、更快速的达到复用节点,更新视图的目的。复用节点就需要通过移动元素的位置来达到更新的目的。
能够移动元素的关键在于:我们需要在新旧 children 的节点中保存映射关系(idxInOld 存在),以便我们能够在旧节点中找到可复用的节点。这时候我们就需要给节点添加唯一标识,也就是我们常说的 key。在没有 key 的情况下,我们是没办法知道新节点是否被复用的可能性,即不知道是否可以通过移动元素位置达到节点复用,更新视图的目的。如果知道了映射关系,我们就很容易判断新节点是否可复用:只需要遍历新 children 中的每一个节点,并去旧节点的 oldKeyToIdx 哈希表中寻找是否存在具有相同 key 值的节点。
如果没有 key 或者使用 index 作为 key,Vue 会使用一种最大限度减少动态元素并且通过创建节点进行原地复用或就地修改相同类型元素的算法来更新,key 的顺序没变,传入的值完全变了。假设我们的组件上定义了一些 dom 的属性或者类名、样式、指令,那么都会被全量的更新,违背了虚拟 DOM 用于减少真实 DOM 操作的原则。而使用 key 时并进一步通过 sameVnode 判断是否是同一节点。如果是同一节点,它会基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素。否则,虽然有相同的 key (例如 index 作为 key 相同)但是不同的元素,则通过 createElm 创建新节点,就地修改。总结起来 key 的作用如下:
- 如遇到 完整地触发组件的生命周期钩子 或 触发过渡 的场景,可以用于强制替换元素/组件而不是重复使用它
- 更准确,基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素,通过移动节点位置,避免原地复用或就地修改来达到复用节点,更新视图的目的。有相同父元素的子元素必须有独特的 key。重复的 key 会造成渲染错误。
- 更快速,利用 key 的唯一性生成 map 对象(oldKeyToIdx 哈希表)来获取对应节点,比遍历方式更快
小结
用组件唯一的 id(一般由后端返回)作为它的 key,实在没有的情况下,可以在获取到列表的时候通过某种规则为它们创建一个 key,并保证这个 key 在组件整个生命周期中都保持稳定。
别用 index 作为 key,和没写基本上没区别,因为不管你数组的顺序怎么颠倒,index 都是 0, 1, 2 这样排列,导致 Vue 会复用错误的旧子节点,做很多额外的工作。
千万别用随机数或者时间戳作为 key,不然旧节点会被全部删掉,新节点重新创建。
// sameVnode
function sameVnode(a, b) {
return (
a.key === b.key &&
((a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)) ||
(isTrue(a.isAsyncPlaceholder) &&
a.asyncFactory === b.asyncFactory &&
isUndef(b.asyncFactory.error)))
);
}
// updateChildren
function updateChildren(
parentElm,
oldCh,
newCh,
insertedVnodeQueue,
removeOnly
) {
let oldStartIdx = 0;
let newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
let oldKeyToIdx, idxInOld, vnodeToMove, refElm;
// removeOnly is a special flag used only by <transition-group>
// to ensure removed elements stay in correct relative positions
// during leaving transitions
const canMove = !removeOnly;
if (process.env.NODE_ENV !== "production") {
checkDuplicateKeys(newCh);
}
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(
oldStartVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
patchVnode(
oldStartVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
);
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
patchVnode(
oldEndVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
);
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
} else {
if (isUndef(oldKeyToIdx))
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx);
if (isUndef(idxInOld)) {
// New element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
} else {
vnodeToMove = oldCh[idxInOld];
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(
vnodeToMove,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
);
oldCh[idxInOld] = undefined;
canMove &&
nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm);
} else {
// same key but different element. treat as new element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
}
}
newStartVnode = newCh[++newStartIdx];
}
}
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
refElm,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
} else if (newStartIdx > newEndIdx) {
removeVnodes(oldCh, oldStartIdx, oldEndIdx);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
新旧节点分别有两个指针,分别指向各自的头部节点和尾部节点。
- 当新旧节点的头部值得对比,进入 patchNode 方法,同时各自的头部指针+1;
- 当新旧节点的尾部值得对比,进入 patchNode 方法,同时各自的尾部指针-1
- 当 oldStartVnode,newEndVnode 值得对比,说明 oldStartVnode 已经跑到了后面,那么就将 oldStartVnode.el 移到 oldEndVnode.el 的后边。oldStartIdx+1,newEndIdx-1
- 当 oldEndVnode,newStartVnode 值得对比,说明 oldEndVnode 已经跑到了前面,那么就将 oldEndVnode.el 移到 oldStartVnode.el 的前边。oldEndIdx-1,newStartIdx+1
当以上 4 种对比都不成立时,通过 newStartVnode.key 看是否能在 oldVnode 中 找到,如果没有则新建节点,如果有则对比新旧节点中相同 key 的 Node,newStartIdx+1。
当循环结束时,这时候会有两种情况:
- oldStartIdx > oldEndIdx,可以认为 oldVnode 对比完毕,当然也有可能 newVnode 也刚好对比完,一样归为此类。此时 newStartIdx 和 newEndIdx 之间的 vnode 是新增的,调用 addVnodes ,把他们全部插进 before 的后边。
- newStartIdx > newEndIdx,可以认为 newVnode 先遍历完,oldVnode 还有节点。此时 oldStartIdx 和 oldEndIdx 之间的 vnode 在新的子节点里已经不存在了,调用 removeVnodes 将它们从 DOM 里删除。
# 总结
- 当数据发生改变时,订阅者 watcher 就会调用 patch 给真实的 DOM 打补丁
- 通过 isSameVnode 进行判断,相同则调用 patchVnode 方法
- patchVnode 做了以下操作:
- 找到对应的真实 dom,称为 el
- 如果都有文本节点且不相等,将 el 文本节点设置为 Vnode 的文本节点
- 如果 oldVnode 有子节点而 VNode 没有,则删除 el 子节点
- 如果 oldVnode 没有子节点而 VNode 有,则将 VNode 的子节点真实化后添加到 el
- 如果两者都有子节点,则执行 updateChildren 函数比较子节点
- updateChildren 主要做了以下操作:
- 设置新旧 VNode 的头尾指针
- 新旧头尾指针进行比较,循环向中间靠拢,根据情况调用 patchVnode 进行 patch 重复流程、调用 createElem 创建一个新节点,从哈希表寻找 key 一致的 VNode 节点再分情况操作。
# 问题
# Q1. Vue 中的 key 有什么作用
key 主要用在 Vue 的虚拟 DOM 的 diff 算法中,是 vnode 的唯一标记,diff 算法中双端两两比较一共有 4 种比较方式,如果以上 4 种比较都没匹配,如果设置了 key,就会用 key 再进行比较。通过这个 key,我们的 diff 操作可以更准确、更快速的达到复用节点,更新视图的目的。复用节点就需要通过移动元素的位置来达到更新的目的。
能够移动元素的关键在于:我们需要在新旧 children 的节点中保存映射关系(idxInOld 存在),以便我们能够在旧节点中找到可复用的节点。这时候我们就需要给节点添加唯一标识,也就是我们常说的 key。在没有 key 的情况下,我们是没办法知道新节点是否被复用的可能性,即不知道是否可以通过移动元素位置达到节点复用,更新视图的目的。如果知道了映射关系,我们就很容易判断新节点是否可复用:只需要遍历新 children 中的每一个节点,并去旧节点的 oldKeyToIdx 哈希表中寻找是否存在具有相同 key 值的节点。
如果没有 key 或者使用 index 作为 key,Vue 会使用一种最大限度减少动态元素并且通过创建节点进行原地复用或就地修改相同类型元素的算法来更新。而使用 key 时并进一步通过 sameVnode 判断是否是同一节点。如果是同一节点,它会基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素。否则,虽然有相同的 key (例如 index 作为 key 相同)但是不同的元素,则通过 createElm 创建新节点,就地修改。总结起来 key 的作用如下:
- 如遇到 完整地触发组件的生命周期钩子 或 触发过渡 的场景,可以用于强制替换元素/组件而不是重复使用它
- 更准确,基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素,通过移动节点位置,避免原地复用或就地修改来达到复用节点,更新视图的目的。有相同父元素的子元素必须有独特的 key。重复的 key 会造成渲染错误。
- 更快速,利用 key 的唯一性生成 map 对象(oldKeyToIdx 哈希表)来获取对应节点,比遍历方式更快
<ul>
<li v-for="item in items" :key="item.id">...</li>
</ul>
<transition>
<span :key="text">{{ text }}</span>
</transition>
2
3
4
5
6
7
- 如果不用 key,Vue 会采用就地复地原则:最小化 element 的移动,并且会尝试尽最大程度在同适当的地方对相同类型的 element,做 patch 或者 复用。
- 如果使用了 key,Vue 会根据 key 的顺序记录 element,曾经拥有了 key 的 element 如果不再出现的话,会被直接 remove 或者destoryed
用+new Date()生成的时间戳作为key,手动强制触发重新渲染
- 当拥有新值的 rerender 作为 key 时,拥有了新 key 的组件出现了,那么旧 key 的组件会被移除,新 key 组件触发渲染
# Q2. keep-alive 原理
keep-alive 主要用于保留组件状态或避免重新渲染。当然 keep-alive 不仅仅是能够保存页面/组件的状态,它还可以避免组件反复创建和渲染,有效提升系统性能。keep-alive 在 vue 中用于实现组件的缓存,当组件切换时不会对当前组件进行卸载,只是挂起。
- include - 字符串或正则表达式。只有名称匹配的组件会被缓存。
- exclude - 字符串或正则表达式。任何名称匹配的组件都不会被缓存。
- max - 数字。最多可以缓存多少组件实例。超出上限使用 LRU 的策略置换缓存数据。其作用就是使用 LRU 的策略防止缓存大量组件,占用大量内存。
- 首次进入组件时:
beforeRouteEnter>beforeCreate>created>mounted>activated> ... ... >beforeRouteLeave>deactivated - 再次进入组件时:
beforeRouteEnter>activated> ... ... >beforeRouteLeave>deactivated
LRU
浏览器中的缓存是一种在本地保存资源副本,它的大小是有限的,当我们请求数过多时,缓存空间会被用满,此时,继续进行网络请求就需要确定缓存中哪些数据被保留,哪些数据被移除,这就是浏览器缓存淘汰策略,最常见的淘汰策略有 FIFO(先进先出)、LFU(最少使用)、LRU(最近最少使用)。
LRU ( Least Recently Used :最近最少使用 )缓存淘汰策略,在操作系统中, LRU 是一种常用的页面置换算法。其目的在于在发生缺页中断时,将最长时间未使用的页面给置换出去。根据数据的历史访问记录来进行淘汰数据,其核心思想是 如果数据最近被访问过,那么将来被访问的几率也更高 ,优先淘汰最近没有被访问到的数据。
<keep-alive> 包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们。<keep-alive> 是一个抽象组件:它自身不会渲染一个 DOM 元素,也不会出现在组件的父组件链中。当组件在 <keep-alive> 内被切换,它的 activated 和 deactivated 这两个生命周期钩子函数将会被对应执行。activated 和 deactivated 将会在 <keep-alive> 树内的所有嵌套组件中触发。
- 一般结合路由和动态组件一起使用,用于缓存组件。
- 提供 include 和 exclude 属性,两者都支持字符串或正则表达式, include 表示只有名称匹配的组件会被缓存,exclude 表示任何名称匹配的组件都不会被缓存 ,其中 exclude 的优先级比 include 高。
- 对应两个钩子函数 activated 和 deactivated ,当组件被激活时,触发钩子函数 activated,当组件被移除时,触发钩子函数 deactivated。
注意
<keep-alive> 是用在其一个直属的子组件被开关的情形。如果你在其中有 v-for 则不会工作。
keep-alive 源码:
// src/core/components/keep-alive.js
export default {
name: "keep-alive",
abstract: true, // 判断当前组件虚拟dom是否渲染成真实dom的关键
props: {
include: patternTypes, // 缓存白名单
exclude: patternTypes, // 缓存黑名单
max: [String, Number] // 缓存的组件大小
},
// 初始化两个对象分别缓存VNode(虚拟DOM)和VNode对应的键集合
created() {
this.cache = Object.create(null); // 缓存虚拟dom
this.keys = []; // 缓存的虚拟dom的键集合
},
/**
* 删除 this.cache 中缓存的 VNode 实例。
* 不是简单地将 this.cache 置为 null,而是遍历调用 pruneCacheEntry 函数删除。
* 删除缓存的 VNode 还要对应组件实例的 destory 钩子函数
*/
destroyed() {
for (const key in this.cache) {
// 删除所有的缓存
pruneCacheEntry(this.cache, key, this.keys);
}
},
/**
* 在 mounted 这个钩子中对 include 和 exclude 参数进行监听
* 然后实时地更新(删除)this.cache 对象数据。
* pruneCache 函数的核心也是去调用 pruneCacheEntry
*/
mounted() {
// 实时监听黑白名单的变动
// pruneCache:遍历 cache,如果缓存的节点名称与传入的规则没有匹配上的话,就把这个节点从缓存中移除
this.$watch("include", val => {
pruneCache(this, name => matched(val, name));
});
this.$watch("exclude", val => {
pruneCache(this, name => !matches(val, name));
});
},
render() {
// 获取第一个子元素的 vnode
const slot = this.$slots.default;
const vnode: VNode = getFirstComponentChild(slot);
const componentOptions: ?VNodeComponentOptions =
vnode && vnode.componentOptions;
if (componentOptions) {
// name 不在 inlcude 中或者在 exlude 中则直接返回 vnode,否则继续进行下一步
// check pattern
const name: ?string = getComponentName(componentOptions);
const { include, exclude } = this;
if (
// not included
(include && (!name || !matches(include, name))) ||
// excluded
(exclude && name && matches(exclude, name))
) {
return vnode;
}
const { cache, keys } = this;
// 获取键,优先获取组件的 name 字段,否则是组件的 tag
const key: ?string =
vnode.key == null
? // same constructor may get registered as different local components
// so cid alone is not enough (#3269)
componentOptions.Ctor.cid +
(componentOptions.tag ? `::${componentOptions.tag}` : "")
: vnode.key;
// --------------------------------------------------
// 下面就是 LRU 算法了,
// 如果在缓存里有则调整,
// 没有则放入(长度超过 max,则淘汰最近没有访问的)
// --------------------------------------------------
// 如果命中缓存,则从缓存中获取 vnode 的组件实例,并且调整 key 的顺序放入 keys 数组的末尾
if (cache[key]) {
vnode.componentInstance = cache[key].componentInstance;
// make current key freshest
remove(keys, key);
keys.push(key);
}
// 如果没有命中缓存,就把 vnode 放进缓存
else {
cache[key] = vnode;
keys.push(key);
// prune oldest entry
// 如果配置了 max 并且缓存的长度超过了 this.max,还要从缓存中删除第一个
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode);
}
}
// keepAlive标记位
vnode.data.keepAlive = true;
}
return vnode || (slot && slot[0]);
}
};
// 删除缓存的VNode还要对应组件实例的destory钩子函数
function pruneCacheEntry(
cache: VNodeCache,
key: string,
keys: Array<string>,
current?: VNode
) {
const cached = cache[key];
if (cached && (!current || cached.tag !== current.tag)) {
cached.componentInstance.$destroyed(); // 执行组件的destroy钩子函数
}
cache[key] = null;
remove(keys, key);
}
// remove 方法(shared/util.js)
export function remove(arr: Array<any>, item: any): Array<any> | void {
if (arr.length) {
const index = arr.indexOf(item);
if (index > -1) {
return arr.splice(index, 1);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
在 keep-alive 缓存超过 max 时,使用的缓存淘汰算法就是 LRU 算法,它在实现的过程中用到了 cache 对象用于保存缓存的组件实例及 key 值,keys 数组用于保存缓存组件的 key ,当 keep-alive 中渲染一个需要缓存的实例时:
- 判断缓存中是否已缓存了该实例,缓存了则直接获取,并调整 key 在 keys 中的位置(移除 keys 中 key ,并放入 keys 数组的最后一位)
- 如果没有缓存,则缓存该实例,若 keys 的长度大于 max (缓存长度超过上限),则移除
keys[0]缓存
<keep-alive> 直接实现了 render 函数,而不是我们常规模板的方式,执行 <keep-alive> 组件渲染的时候,就会执行到这个 render 函数,接下来我们分析一下它的实现。
LRU 的核心思想是如果数据最近被访问过,那么将来被访问的几率也更高,所以我们将命中缓存的组件 key 重新插入到 this.keys 的尾部,这样一来,this.keys 中越往头部的数据即将来被访问几率越低,所以当缓存数量达到最大值时,我们就删除将来被访问几率最低的数据,即 this.keys 中第一个缓存的组件。这也就之前强调的已缓存组件中最久没有被访问的实例会被销毁掉的原因.
render () {
const slot = this.$slots.defalut
const vnode: VNode = getFirstComponentChild(slot) // 找到第一个子组件对象
const componentOptions : ?VNodeComponentOptions = vnode && vnode.componentOptions
if (componentOptions) { // 存在组件参数
// check pattern
const name: ?string = getComponentName(componentOptions) // 组件名
const { include, exclude } = this
if (// 条件匹配
// not included
(include && (!name || !matches(include, name)))||
// excluded
(exclude && name && matches(exclude, name))
) {
return vnode
}
const { cache, keys } = this
// 定义组件的缓存key
const key: ?string = vnode.key === null ? componentOptions.Ctor.cid + (componentOptions.tag ? `::${componentOptions.tag}` : '') : vnode.key
if (cache[key]) { // 已经缓存过该组件
vnode.componentInstance = cache[key].componentInstance
remove(keys, key)
keys.push(key) // 调整key排序
} else {
cache[key] = vnode //缓存组件对象
keys.push(key)
if (this.max && keys.length > parseInt(this.max)) {
//超过缓存数限制,将第一个删除
pruneCacheEntry(cahce, keys[0], keys, this._vnode)
}
}
vnode.data.keepAlive = true //渲染和执行被包裹组件的钩子函数需要用到
}
return vnode || (slot && slot[0])
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
- 获取 keep-alive 包裹着的第一个子组件对象及其组件名;
- 根据设定的黑白名单(如果有)进行条件匹配,决定是否缓存。不匹配,直接返回组件实例(VNode),否则执行第三步;
- 根据组件 ID 和 tag 生成缓存 Key,并在缓存对象中查找是否已缓存过该组件实例。如果存在,直接取出缓存值并更新该 key 在 this.keys 中的位置(更新 key 的位置是实现 LRU 置换策略的关键),否则执行第四步;
- 在 this.cache 对象中存储该组件实例并保存 key 值,之后检查缓存的实例数量是否超过 max 设置值,超过则根据 LRU 置换策略删除最近最久未使用的实例(即是下标为 0 的那个 key);
- 最后并且很重要,将该组件实例的 keepAlive 属性值设置为 true。
<keep-alive> 组件是一个抽象组件,它的实现通过自定义 render 函数并且利用了插槽,并且 <keep-alive> 缓存 vnode,了解组件包裹的子元素——也就是插槽是如何做更新的。且在 patch 过程中对于已缓存的组件不会执行 mounted,所以不会有一般的组件的生命周期函数但是又提供了 activated 和 deactivated 钩子函数。
# 缓存后如何获取数据?
解决方案可以有以下两种:
- beforeRouteEnter
- actived
beforeRouteEnter
每次组件渲染的时候,都会执行beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
},
2
3
4
5
6
7
actived
在keep-alive缓存的组件被激活的时候,都会执行actived钩子
activated(){
this.getData() // 获取数据
},
2
3
注意:服务器端渲染期间avtived不被调用