# 网络方面优化
减小请求资源体积,减少网络请求、利用网络缓存、利用预解析、预建连、预请求、路由懒加载、使用高性能网络协议,最小化 HTTP 请求大小、最小化 HTTP 响应大小,减少不必要的重定向。
使用 http/2 协议,同时做好域名收敛。利用 HTTP/2 提供的基于帧的解析速度,利用二进制分帧层的多路复用,首部压缩、优先级、流量控制,服务器推送等特性,提升网络传输速率和吞吐率,降低网络延迟,停止合并文件、停止内联资源、停止细分域名。
使用 CDN 部署和加载静态资源。使用 CDN 降低网络延时即丢包率,分布式 CDN 增加并发连接,CDN 长缓存,加速下载静态资源,提升静态资源访问速度。
DNS 预解析。常用于 CDN 域名场景,减少 DNS 解析耗时。
<link rel="dns-prefetch" href="cdn.example.com">preconnect 提前建立网络连接。常用于 Server API 等域名,兼容性更好。
<link rel="preconnect" href="example.com">开启 gzip/br 压缩。使用 gzip/br 压缩编码技术,减小资源体积。
利用浏览器缓存。利用浏览器缓存(强缓存与协商缓存)与 Nginx 代理层缓存,缓存静态资源文件。
资源加载优化,减少网络请求次数。通过压缩、分包、按需加载、字体图标、高性能格式图片、缓存优化等,减少网络请求次数,但需要找到合理的平衡点。
- 压缩静态资源文件
- 合理进行 js、css 分包,并利用 HTTP/2
- 减少外部脚本数量
- 懒加载或者按需加载
- 行内图片(Base64编码)、图片懒加载、使用 webp 等高性能图片格式
- 使用字体图标,iconfont 代替图片图标
- 浏览器缓存(强缓存与协商缓存)
提升 HTTPS 性能。通过有效的优化手段,如 OCSP Stapling、Session Resume 等等,提升 HTTPS 性能。
# 使用 HTTP/2 协议
使用 HTTP/2 协议,同时做好域名收敛。
使用 HTTP/1 时,为了尽可能减少请求数,需要做合并文件、雪碧图、资源内联等优化工作,但是这无疑造成了单个请求内容变大延迟变高的问题,且内嵌的资源不能有效地使用缓存机制。
HTTP/2 的优化需要不同的思维方式。应该专注于网站的缓存调优,而不是担心如何减少 HTTP 请求数。通用的法则是,传输轻量、细粒度的资源,以便独立缓存和并行传输。停止合并文件、停止内联资源、停止细分域名。
HTTP2.0 大幅度的提高了 web 性能,在 HTTP1.1 完全语义兼容的基础上,进一步减少了网络的延迟。实现低延迟高吞吐量。对于前端开发者而言,减少了优化工作。Http2 提供了以下一些新特性,对性能优化有一定帮助。
解析速度快
服务器解析 HTTP1.1 的请求时,必须不断地读入字节,直到遇到分隔符 CRLF 为止。而解析 HTTP2 的请求就不用这么麻烦,因为 HTTP2 是基于帧的协议,每个帧都有表示帧长度的字段。
二进制分帧
将所有传输信息分割为更小的消息和帧,并对它们采用二进制格式的编码将其封装。二进制分帧主要是为下文中的各种特性提供了基础。它能把一个数据划分封装为更小更便捷的数据。首先是在单链接多资源方式中,减少了服务端的链接压力,内存占用更少,链接吞吐量更大。这一点可以结合下文中的多路复用来体会。另一方面,由于 TCP 链接的减少而使网络拥塞状态得以改善,同时慢启动时间的减少。使拥塞和丢包恢复的速度更快。
多路复用
HTTP1.1 如果要同时发起多个请求,就得建立多个 TCP 连接,因为一个 TCP 连接同时只能处理一个 HTTP1.1 的请求。在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为多路复用。
基于二进制分帧层,原来
Headers + Body的报文格式如今被拆分成了一个个二进制的帧,用Headers帧存放头部字段,Data帧存放请求体数据。HTTP2.0 可以在共享 TCP 链接的基础上同时发送请求和响应。同一个请求和响应用一个流来表示,并有唯一的流 ID 来标识。多个请求和响应在 TCP 连接中可以乱序发送,到达目的地后再通过流 ID 重新组建。通过并行交错的发送请求和响应,这些请求和响应之间互不影响,消除不必要的延迟,减少页面加载时间。首部压缩 - HPACK 算法
HTTP2 提供了首部压缩功能。HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送。每个新的首部键值对要么追加到当前表的末尾,要么替换表中之前的值。首部压缩可以使报头更紧凑,更快速传输,有利于移动网络环境。减少每次通讯的数据量,使网络拥塞状态得以改善。
它使用了下面这三种方法进行压缩:
静态字典表:由61个常规header域和一些预定义的values组成的预定义字典表。
动态字典表:在连接中遇到的实际header域的列表。这个字典表有大小限制,新的key进来,旧的key可能会被移除。
Huffman编码:静态的Huffman编码 (opens new window)可以对任何字符串进行编码:名称或者是值。这种编码特定地用在HTTP的request/response头中,ASCII码和小写字母的编码会更短。
请求优先级
客户端明确指定优先级,服务端可以根据这个优先级作为交互数据的依据,优先将最高优先级的帧发送给客户端。
流量控制
由于一个 TCP 连接流量带宽(根据客户端到服务器的网络带宽而定)是固定的,当有多个请求并发时,一个请求占的流量多,另一个请求占的流量就会少。流量控制可以对不同的流的流量进行精确控制。
服务器推送(Server Push)
服务端根据客户端的请求,提前返回多个响应,推送额外的资源给客户端。服务端推送是一种在客户端请求之前发送数据的机制。在 HTTP2.0 中,服务器可以对一个客户端的请求发送多个响应。如果一个请求是由你的主页发送的,服务器可能会响应主页内容、logo 以及样式表,因为他知道客户端会用到这些东西。这样不但减轻了数据传送冗余步骤,也加快了页面响应的速度,提高了用户体验。
Server-Push 主要是针对资源内联做出的优化,相较于 http/1.1 资源内联的优势: - 客户端可以缓存推送的资源 - 客户端可以拒收推送过来的资源 - 推送资源可以由不同页面共享 - 服务器可以按照优先级推送资源
支持 Server Worker - 非 HTTP2 特性
Service Worker 借鉴了 Web Worker 的 思路,即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问 DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能。其中的离线缓存就是 Service Worker Cache。Service Worker 同时也是 PWA 的重要实现机制。
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker 的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全
# 域名发散与收敛
域名收敛:就是将静态资源放在一个域名下,减少DNS解析的开销。域名收敛多用与移动端,提高性能,因为 dns 解析是是从后向前迭代解析,如果域名过多性能会下降,增加 DNS 的解析开销。
域名发散:是将静态资源放在多个子域名下,就可以多线程下载,提高并行度,使客户端加载静态资源更加迅速。域名发散是 PC 端为了利用浏览器的多线程并行下载能力
现在,各大浏览器都已经提升了资源的下载数,所以,域名分散的必要性也就没这么大了。一般来说,域名分散的数量最好在 3 以下,否则性能反而下降。
浏览器有并发限制,是为了防止 DDoS 攻击
分布式拒绝服务攻击DDoS是一种基于DoS的特殊形式的拒绝服务攻击,是一种分布的、协同的大规模攻击方式。单一的 DDoS 攻击一般是采用一对一方式的,它利用网络协议和操作系统的一些缺陷,采用欺骗和伪装的策略来进行网络攻击,使网站服务器充斥大量要求回复的信息,消耗网络带宽或系统资源,导致网络或系统不胜负荷以至于瘫痪而停止提供正常的网络服务。与 DDoS 攻击由单台主机发起攻击相比较,分布式拒绝服务攻击 DDoS 是借助数百、甚至数千台被入侵后安装了攻击进程的主机同时发起的集团行为。
这个方法是通过增加域名来解除并发限制,那有没有方法不用增加域名来解除并发限制呢?- SPYD
# SPYD
SPDY 是 google 主导的一种新型通信方式,主要的特点就是多路复。他的目的就是致力于取消 max connections 上限。SPDY 协议能够完成多路复用的加密全双工通道,显著提高非 wifi 环境下的网络体验。
SPDY 具体的优势在哪里?
解决了 HTTP 只能 One request per connection. 当连接完成后,可以实现并行下载多个资源文件
服务器推的技术。和 SSE 的理念类似,不过更靠底层。直接可以实现无需用户等待,直接后台发资源(感觉就像写APP了,有木有)
请求头的复用。当你前几次的请求头内容没多大变化的时候,就会省去几个相同的,实现 Header Compression
数据压缩。 在HTTP1.1 有 Content-Encoding: gzip, Transfer-Encoding: chunked. 来显式表明开启文本压缩。
强制使用 SSL 传输协议。Google 认为 Web 将来的发展方向一定是安全的网络链接,所有请求 SSL 加密后,信息传输更加安全。
那如何开启 SPDY 呢?
- 使用 nginx 的用户,可以下载一个 ngx_http_spdy_module 的模块
- 使用 apache 的用户,可以下载一个 mod_spdy module 的模块
# 使用 CDN 部署静态资源
使用 CDN 加速下载静态资源,提升静态资源访问速度
内容分发网络(CDN)是一组分布在多个不同地理位置的 Web 服务器。当服务器离用户越远时,经过的路由器越多,延迟越高。CDN 就是为了解决这一问题,在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间。用户请求资源时,就近返回节点上缓存的资源,而不需要每个用户的请求都回您的源站获取,避免网络拥塞、缓解源站压力,保证用户访问资源的速度和体验。当然不仅仅如此,CDN 还可以分担 IDC(运营商数据服务器) 压力。CDN 可以通过不同的域名来加载文件,从而使下载文件的并发连接数大大增加,且 CDN 具有更好的可用性,更低的网络延迟和丢包率 。
由于 CDN 会为资源开启长时间的缓存,例如用户从 CDN 上获取了 index.html,即使之后替换了 CDN 上的 index.html,用户那边仍会在使用之前的版本直到缓存时间过期。业界做法:
- HTML 文件:放在自己的服务器上且使用协商缓存,不接入 CDN
- 静态的 JS、CSS、图片等资源:开启 CDN 和强缓存,同时文件名带上由内容计算出的 Hash 值,这样只要内容变化 hash 就会变化,文件名就会变化,就会被重新下载而不论缓存时间多长。
减少 DNS 查询次数与解析时间 - DNS 预解析
HTTP1.x 版本的协议下,浏览器会对于向同一域名并行发起的请求数限制在 4~8 个。那么把所有静态资源放在同一域名下的 CDN 服务上就会遇到这种限制,所以可以把他们分散放在不同的 CDN 服务上,例如 JS 文件放在 js.cdn.com 下,将 CSS 文件放在 css.cdn.com 下等。这样又会带来一个新的问题:增加了域名解析时间,这个可以通过 dns-prefetch(DNS 预解析) 来解决 <link rel='dns-prefetch' href='//js.cdn.com'> 来缩减域名解析的时间。形如 //xx.com 这样的 URL 省略了协议,这样做的好处是,浏览器在访问资源时会自动根据当前 URL 采用的模式来决定使用 HTTP 还是 HTTPS 协议。
总之,构建需要满足以下几点:
- 为了解决 Nginx 目录存储过大 + 结合 CDN 提升访问速度,采用了 Nginx 反向代理 + 将静态资源上传到 CDN。
- 为了上传 CDN,我们需要按环境动态构造 publicPath + 按环境构造 CDN 上传目录。
- 静态资源导入的 URL 要变成指向 CDN 服务的绝对路径的 URL
- 静态资源的文件名需要带上根据内容计算出的 Hash 值
- 不同类型资源放在不同域名的 CDN 上
- CDN 利用 DNS 预解析
webpack 配置资源存放 CDN
- 体积较大的第三方依赖单独拆出来放到 CDN 上,这样这个依赖既不会占用打包资源,也不会影响最终包体积。
- 如果一个依赖有直接打包压缩好的单文件 CDN 资源,就可以直接使用。例如 vue.min.js
const ExtractTextPlugin = require('extract-text-webpack-plugin');
const { WebPlugin } = require('web-webpack-plugin');
module.exports = {
output: {
filename: '[name]_[chunkhash:8].js',
path: path.resolve(__dirname, 'dist'),
publicPath: '//js.cdn.com/id/', // 指定CSS文件中导入的图片等资源存放的CDN地址
},
module: {
rules: [
{
test: /\.css/,
use: ExtractTextPlugin.extract({
use: ['css-loader?minimize'],
publicPath: '//img.cdn.com/id/', // 指定CSS文件中导入的图片等资源存放的CDN地址
}),
},
{
test: /\.png/,
use: ['file-loader?name=[name]_[hash:8].[ext]'], // 为输出的PNG文件名加上Hash值
},
],
},
plugins: [
new WebPlugin({
template: './template.html',
filename: 'index.html',
stylePublicPath: '//css.cdn.com/id/', //指定存放CSS文件的CDN地址
}),
new ExtractTextPlugin({
filename: `[name]_[contenthash:8].css`, //为输出的CSS文件加上Hash
}),
],
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
如果我们想引用一个库,但是又不想让 webpack 打包,并且又不影响我们在程序中以 import、require 或者 window/global 全局等方式进行使用,那就可以通过配置 externals。externals 配置选项提供了「从输出的 bundle 中排除依赖」的方法。
使用 externals 可以防止某些库被打包,而通过其他方式引用库(如 CDN),这样做的好处是当更新代码时不会影响库代码的缓存,用户只需下载新的代码即可。当然我们也可以使用 chunk 来把不常更新的库打包在另一个文件。
// 从 CDN 引入 React
<script crossorigin src="https://unpkg.com/react@16/umd/react.production.min.js" defer></script>
<script crossorigin src="https://unpkg.com/react-dom@16/umd/react-dom.production.min.js" defer></script>
<script src="./dist/index.js" defer></script>
module.exports = {
externals: {
react: 'React',
'react-dom': 'ReactDOM',
},
};
2
3
4
5
6
7
8
9
10
注意
可以借助 html-webpack-plugin 将 CDN 文件打入 html。在 html 中配置的 CDN 引入脚本一定要在 body 内的最底部,因为:
- 如果放在 body 上面或 header 内,则加载会阻塞整个页面渲染。
- 如果放在 body 外,则会在业务代码被加载之后加载,模块中使用了该模块将会报错。
# CDN 原理
# 1. 没有的 CDN 网路请求过程
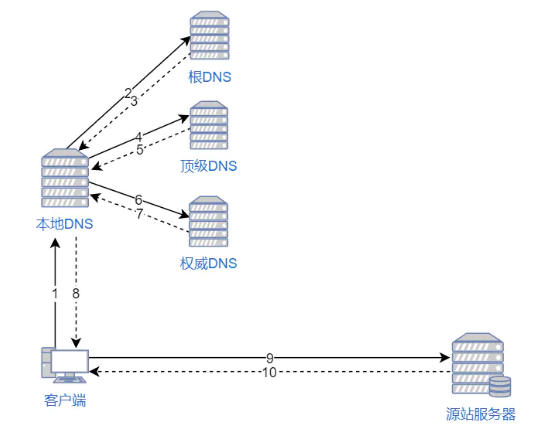
- 浏览器要将域名解析为 IP 地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器、顶级域名服务器、权限服务器发出请求,得到网站服务器的 IP 地址。
- 本地 DNS 将 IP 地址发回给浏览器,浏览器向网站服务器 IP 地址发出请求并得到资源。
# 2. 有 CDN 服务器网路请求过程
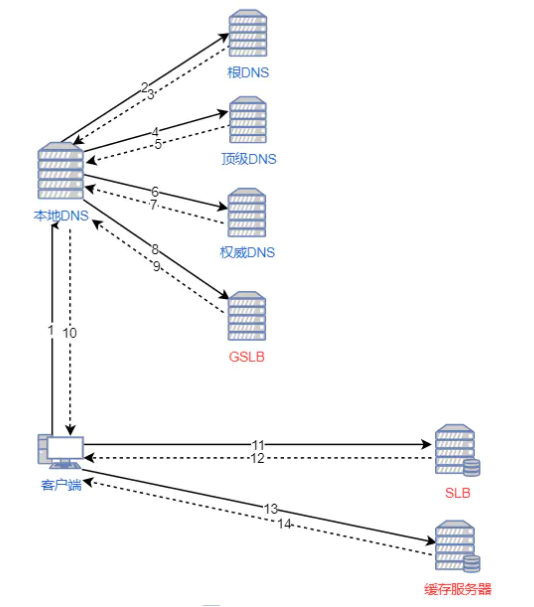
- 浏览器要将域名解析为 IP 地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器、顶级域名服务器、权限服务器发出请求,得到全局负载均衡系统(GSLB)的 IP 地址。
- 本地 DNS 再向 GSLB 发出请求,GSLB 的主要功能是根据本地 DNS 的 IP 地址判断用户的位置,筛选出距离用户较近的本地- 负载均衡系统(SLB),并将该 SLB 的 IP 地址作为结果返回给本地 DNS。
- 本地 DNS 将 SLB 的 IP 地址发回给浏览器,浏览器向 SLB 发出请求。
- SLB 根据浏览器请求的资源和地址,选出最优的缓存服务器发回给浏览器。
- 浏览器再根据 SLB 发回的地址重定向到缓存服务器。
- 如果缓存服务器有浏览器需要的资源,就将资源发回给浏览器。如果没有,就向源服务器请求资源,再发给浏览器并缓存在本地。
# DNS 预解析
一般来说,在前端优化中与 DNS 有关的有两点: 减少 DNS 请求次数和 DNS Prefetch。
DNS 预解析(pre-resolve)
- 提前解析主机地址,以减少 DNS 延迟 TCP 预连接(pre-connect) 提前连接到目标服务器,以减少 TCP 握手延迟资源预加载(prefetching) 提前加载页面的核心资源,以加载页面显示页面预渲染(prerendering)。
- 提前获取整个页面和相关子资源,这样可以做到及时显示。
- 每一个决策都包含着一个或多个的优化, 用来克服大量的限制因素. 不过毕竟都只是预测性的优化策略,如果效果不理想,就会引入多余的处理和网络传输。甚至可能会带来一些加载时间上的负体验
DNS 预解析具体用法:
// 用 meta 信息来告知浏览器, 当前页面要做 DNS 预解析
<meta http-equiv="x-dns-prefetch-control" content="on">
// 在页面header中使用 link 标签来强制对 DNS 预解析:
<link rel="dns-prefetch" href="//www.zhix.net">
2
3
4
注意:dns-prefetch 需慎用,多页面重复 DNS 预解析会增加重复 DNS 查询次数,因为有开发者指出 禁用 DNS 预读取能节省每月100亿的DNS查询。
// 如果需要禁止隐式的 DNS Prefetch
<meta http-equiv="x-dns-prefetch-control" content="off">
2
# 开启 gzip/brotli 压缩
gzip 编码是改进 web 应用程序性能的技术,web 服务器和客户端(浏览器)必须同时支持 gzip。gzip 压缩效率非常高,通常可达 70% 压缩率。相比 gzip,br 压缩具有更高的压缩比和更快的压缩性能。
response header 中 Content-Encoding: gzip
webpack 中使用 CompressionWebpackPlugin 插件进行压缩
if (process.env.NODE_ENV === 'production') {
plugins.push(new CompressionWebpackPlugin({
filename: '[path].gz[query]',
algorithm: 'gzip',
test: new RegExp(`\\.(${productionGzipExtensions.join('|')})$`),
threshold: 10240,
minRatio: 0.8,
deleteOriginalAssets: false
}))
}
2
3
4
5
6
7
8
9
10
同时服务端需支持 gzip,以 Nginx 配置为例:
gzip on;
gzip_static on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_comp_level 2;
gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php application/vnd.ms-fontobject font/ttf font/opentype font/x-woff image/png image/jpeg image/svg+xml image/gif;
gzip_vary off;
gzip_disable "MSIE [1-6]\.";
2
3
4
5
6
7
8
以 Node 服务端为例:
// npm install compression —save
var compression = require('compression');
var app = express();
app.use(compression())
2
3
4
5
# 利用浏览器缓存
主要使用 强缓存 与 协商缓存 机制,具体参考 浏览器缓存
一个较为合理的缓存方案:
- HTML 频繁更新的资源:使用协商缓存。
- CSS、JS、图片等静态稳定资源:使用强缓存,且文件命名带上 hash 值。
# 强缓存
强缓存是最彻底的缓存,无需向服务器发送请求,通常用于 css、js、图片等静态资源。浏览器发送请求后会先判断本地是否有缓存。如果无缓存,则直接向服务器发送请求;如果有缓存,则判断缓存是否命中强缓存,如果命中则直接使用本地缓存,如果没命中则向服务器发送请求。判断是否命中本地缓存的方法有两种:Expires 和 Cache-Control。
# Expires
Expires 是http1.0的响应头,代表的含义是资源本地缓存的过期时间,由服务器设定。服务器返回给浏览器的响应头中如果包含Expires字段,浏览器发送请求时拿当前时间和Expires字段值进行比较,判断资源缓存是否失效。
# Cache-Control
Cache-Control 是http1.1中新增的字段。由于Expires设置的是资源的具体过期时间,如果服务器时间和客户端时间不一样,就会造成缓存错乱,比如人为调节了客户端的时间,所以设置资源有效期的时长更合理。http1.1 添加了 Cache-Control 的 max-age 字段。max-age 代表的含义是资源有效期的时长,是一个相对时长,单位为s。浏览器再次发送请求时,会把第一次请求的时间和 max-age 字段值相加和当前时间比较,以此判断是否命中本地缓存。max-age 使用的都是客户端时间,比 Expires 更可靠。如果 max-age 和Expires 同时出现,max-age 的优先级更高。Cache-Control 提供了更多的字段来控制缓存:
- no-store:不判断强缓存和协商缓存,服务器直接返回完整资源
- no-cache:不判断强缓存,每次都需要向浏览器发送请求,进行协商缓存判断
- public:指示响应可被任何缓存区缓存
- private:通常只为单个用户缓存,不允许任何共享缓存对其进行缓存,通常用于用户个人信息
# 协商缓存
协商缓存的判断在服务器端进行,判断是否命中的依据就是这次请求和上次请求之间资源是否发生改变。未发生改变则命中,发生改变则未命中。判断文件是否发生改变的方法有两个:Last-Modified、If-Modified-Since 和 Etag、If-None-Match。
# Last-Modified、If-Modified-Since
Last-Modified 是 http1.0 中的响应头字段,代表请求的资源最后一次的改变时间。If-Modified-Since 是 http1.0 的请求头,If-Modified-Since 的值是上次请求服务器返回的Last-Modified 的值。浏览器第一次请求资源时,服务器返回 Last-Modified,浏览器缓存该值。浏览器第二次请求资源时,用于缓存的 Last-Modified 赋值给 If-Modified-Since,发送给服务器。服务器判断 If-Modified-Since 和服务器本地的 Last-Modified 是否相等。如果相等,说明资源未发生改变,命中协商缓存;如果不相等,说明资源发生改变,未命中协商缓存。
# Etag、If-None-Match
Last-Modified、If-Modified-Since 使用的都是服务器提供的时间,所以相对来说还是很可靠的。但是由于修改时间的精确级别或者定期生成文件这种情况,会造成一定的错误。所以 http1.1 添加 Etag、If-None-Match 字段,完善协商缓存的判断。Etag 是根据资源文件内容生成的资源唯一标识符,一旦资源内容发生改变,Etag 就会发生改变。基于内容的标识符比基于修改时间的更可靠。If-None-Match 的值是上次请求服务器返回的 Etag 的值。Etag、If-None-Match 的判断过程和 Last-Modified、If-Modified-Since一致,Etag、If-None-Match 的优先级更高。
强缓存的优势很明显,无需向服务器发送请求,节省了大量的时间和带宽。但是有一个问题,缓存有效期内想更新资源怎么办?如何使强缓存失效,是问题的关键。通常的解决方法是通过 webpack 文件指纹策略添加占位符,更新文件名,文件名不一样的话,浏览器就会重新请求资源。
下面以 Nginx 为例配置缓存,Nginx 可配置的缓存又有 2 种:
- 客户端的缓存(一般指浏览器的缓存)。
- 服务端的缓存(Nginx代理层缓存,使用 proxy-cache 实现的)。
具体配置参考 Nginx 静态资源服务器 (opens new window)
# 减少网络请求
一个完整的 HTTP 请求需要经历 DNS 查找,TCP 握手,浏览器发出 HTTP 请求,服务器接收请求,服务器处理请求并发回响应,浏览器接收响应等过程。http 80% 响应时间花在了图片、样式、脚本等资源下载上。我们不能减少页面请求资源,所以通过将资源整合到一个文件,从而减少 HTTP 请求次数,来达到优化目的。通过以下手段减少 http 请求次数:
- 压缩静态资源文件
- 合理进行js、css分包,并利用 HTTP/2
- 减少外部脚本数量
- 懒加载或者按需加载
- 行内图片(Base64编码)、图片懒加载、使用 webp 等高性能图片格式
- 使用字体图标,iconfont 代替图片图标
- 浏览器缓存(强缓存与协商缓存)
Webpack 只是一个工程化构建工具,没有能力决定应用最终在网络分发时的缓存规则,但我们可以调整产物文件的名称(通过 Hash)与内容(通过 Code Splitting (opens new window)),使其更适配 HTTP 持久化缓存策略。Webpack 提供了一种模板字符串(Template String (opens new window))能力,用于根据构建情况动态拼接产物文件名称(output.filename (opens new window)),规则稍微有点复杂,但从性能角度看,比较值得关注的是其中的几个 Hash 占位符,包括:
[fullhash]:整个项目的内容 Hash 值,项目中任意模块变化都会产生新的fullhash;[chunkhash]:产物对应 Chunk 的 Hash,Chunk 中任意模块变化都会产生新的chunkhash;[contenthash]:产物内容 Hash 值,仅当产物内容发生变化时才会产生新的contenthash,因此实用性较高。
每个产物文件名都会带上一段由产物内容计算出的唯一 Hash 值,文件内容不变,Hash 也不会变化,这就很适合用作 HTTP 持久缓存 (opens new window) 资源。此时,产物文件不会被重复下载,一直到文件内容发生变化,引起 Hash 变化生成不同 URL 路径之后,才需要请求新的资源文件,能有效提升网络性能,因此,生产环境下应尽量使用 [contenthash] 生成有版本意义的文件名。
Hash 规则很好用,不过有一个边际 Case 需要注意:异步模块变化会引起主 Chunk Hash 同步发生变化。因为在 主 Chunk 中需要记录异步 Chunk 的真实路径。异步 Chunk 的路径变化自然也就导致了父级 Chunk 内容变化,此时可以用 optimization.runtimeChunk 将这部分代码抽取为单独的 Runtime Chunk。
建议至少为生成环境启动 [contenthash] 功能,并搭配 optimization.runtimeChunk 将运行时代码抽离为单独产物文件。
# 提升 HTTPS 性能
通过有效的优化手段,如 OCSP Stapling、Session Resume 等等,提升 HTTPS 性能。
# OCSP Stapling
# PKI 证书的生命周期
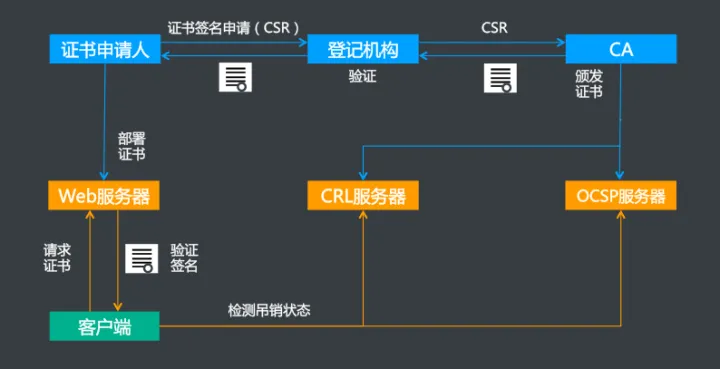
对于一个可信任的 CA 机构颁发的有效证书,在证书到期之前,只要 CA 没有将该证书吊销,那么这个证书就是有效可信任的。但是,由于某些特殊原因(比如私钥泄漏,证书信息有误,CA 有漏洞被黑客利用,颁发了其他域名的证书等等),需要吊销某些证书。那浏览器或者客户端如何知道当前使用的证书已经被吊销了呢?通常有两种方式:CRL 和 OCSP。
# CRL
CRL(Certificate Revocation List,证书吊销列表) 是由 CA 机构维护的一个列表,列表中包含已经被吊销的证书序列号和吊销时间。浏览器可以定期去下载这个列表用于校验证书是否已被吊销。可以看出,CRL 只会越来越大,而且当一个证书刚被吊销后,浏览器在更新 CRL 之前还是会信任这个证书的,实时性较差。这时,OCSP弥补了这一点缺陷。
# OCSP
OCSP(Online Certificate Status Protocol,在线证书状态协议),是一个在线证书查询接口,它建立一个可实时响应的机制,让浏览器发送查询证书请求到 CA 服务器,然后 CA 服务器实时响应验证证书是否合法有效,这样可以实时查询每一张证书的有效性,解决了 CRL 的实时性问题。
简单说,OCSP 在线证书状态协议。它是一个用于检查证书状态的协议,客户端使用此协议来检查证书是否被撤销。但是 OCSP 又有另外两个问题:CA 服务器上的隐私和性能问题。
由于 OCSP 要求浏览器直接请求第三方 CA 以确认证书的有效性,因此会损害隐私。CA 知道什么网站访问了该 CA 以及哪些用户访问了该网站。而这些数据对于跨国业务网站或者政企网站尤为敏感。
另一方面,某些客户端会在 SSL 握手时去实时查询 OCSP 接口,并在获得查询结果前会阻塞后续流程,在网络不佳时(尤其是内陆地区)会造成较长时间的页面空白,降低了 HTTPS 性能,严重影响用户体验。在服务器上部署 OCSP Stapling 将可以解决以上问题。
# OCSP Stapling
OCSP Stapling,是指服务端主动获取 OCSP 查询结果并随着握手协商时一起发送给客户端,从而让客户端免去自己验证的过程,提高 TLS 握手效率。OCSP Stapling 将在很大程度上解决网站设置 HTTPS 后访问速度变慢的问题。
其原理是:网站服务器将自行查询 OCSP 服务器并缓存响应结果,然后在与浏览器进行 TLS 连接时返回给浏览器,这样浏览器就不需要再去查询了。因此,浏览器客户端也不再需要向任何第三方披露用户的浏览习惯,完美解决了隐私问题。同时,当有客户端向服务器发起 SSL 握手请求时,服务器将证书的 OCSP 信息随证书链一同发送给客户端,从而避免了客户端验证会产生的阻塞问题,提升了HTTPS性能。由于 OCSP 响应是无法伪造的,因此这一过程也不会产生额外的安全问题。
所以,在服务器上部署OCSP Stapling能极大的提高安全稳定性能、使网站访问速度更快,用户体验更好。
Nginx 配置支持 OCSP Stapling
server {
listen 443 ssl;
server_name www.xxx.cn;
ssl_stapling on;
ssl_stapling_verify on;
resolver 8.8.8.8 8.8.4.4 valid=300s; #设置 OCSP 请求的 DNS 服务器地址
resolver_timeout 5s;
ssl_trusted_certificate ca.pem; # ca.pem 为证书的中级 CA 证书
}
2
3
4
5
6
7
8
9
10
# 复用 Session
复用 Session(Session Resume),实现简化握手。复用 Session 的好处有两个:
- 减少了 CPU 消耗,因为不需要进行非对称密钥交换的计算。
- 提升访问速度,不需要进行完全握手阶段二,节省了一个 RTT 和计算耗时。
TLS协议目前提供两种机制实现 Session Resume
Session Cache:使用Client Hello中的Session ID查询服务端的Session Cache,如果服务端有对应的缓存,则直接使用已有的Session信息提前完成握手,称为简化握手。Session Cache有两个缺点:
- 需要消耗服务端内存来存储Session内容。
- 目前的开源软件包括Nginx,Apache只支持单机多进程间共享缓存,不支持多机间分布式缓存,对于百度或者其他大型互联网公司而言,单机Session Cache几乎没有作用。
Session Ticket:Server将Session信息加密成Ticket发送给浏览器,浏览器后续握手请求时会发送Ticket,Server端如果能成功解密和处理Ticket,就能完成简化握手。Session Ticket的优点是不需要服务端消耗大量资源来存储Session内容。Session Ticket的缺点:
- Session Ticket只是TLS协议的一个扩展特性,目前的支持率不是很广泛,只有60%左右。
- Session Ticket需要维护一个全局的key来加解密,需要考虑key的安全性和部署效率。
总体来讲,Session Ticke t的功能特性明显优于 Session Cache