# Webpack 相关
# Babel Plugin 开发
Babel 插件的作用是在构建时通过修改 JavaScript 代码的 AST 来实现代码转换,Babel 插件工作流程可以分为以下几个步骤:
- 解析源代码:Babel 将 JavaScript 源代码解析为 AST(抽象语法树)。
- 遍历 AST:Babel 插件遍历 AST,根据需要修改 AST 节点。
- 生成代码:Babel 将修改后的 AST 转换回 JavaScript 代码,并输出最终的代码
一个简单的 Babel 插件的核心是一个函数,它接收 babel 对象作为参数,并返回一个包含 visitor 对象的配置。visitor 对象定义了对 AST 节点的访问规则。
// index.js
module.exports = function (babel) {
const { types: t } = babel; // 解构出 types API,用于创建和判断 AST 节点
return {
visitor: {
CallExpression(path) {
// 检查是否是 console.log 调用
if (t.isMemberExpression(path.node.callee) &&
path.node.callee.object.name === 'console' &&
path.node.callee.property.name === 'log') {
// 替换为 console.warn
path.node.callee.property.name = 'warn';
}
},
},
};
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
babel-types 提供了许多工具函数,用于创建、判断和修改 AST 节点。常见的函数包括:
- 节点判断:
t.isIdentifier(node):判断节点是否是 Identifier。t.isCallExpression(node):判断节点是否是 CallExpression。
- 节点创建:
t.callExpression(callee, args):创建一个 CallExpression 节点。t.identifier(name):创建一个 Identifier 节点。
- 节点修改:
t.updateExpression():更新现有的节点,返回修改后的新节点。
visitor 对象是插件的核心,包含了一组方法,每个方法用于访问特定类型的 AST 节点。常见的节点类型有:
- Identifier:标识符(如变量、函数名)。
- CallExpression:函数调用。
- Literal:字面量(如数字、字符串)。
- MemberExpression:成员访问(如 object.property)。
- VariableDeclaration:变量声明。
Babel 插件提供了 pre、visitor 和 post 钩子来让插件在不同阶段进行操作:
- pre:在 Babel 执行转换之前执行,可以用来做一些初始化操作。
- visitor:遍历 AST 节点并修改节点。
- post:在转换后执行,可以用于最终操作,如调试输出等。
# Webpack Plugin 开发
Webpack 插件是 Webpack 中非常强大的机制,它通过与 Webpack 的生命周期钩子(Hooks)交互,允许开发者在构建的不同阶段插入自定义逻辑,进行优化、修改输出内容等。Webpack 插件是用来在 Webpack 构建过程中,做一些自定义的操作,例如:
- 修改输出内容:比如修改打包结果,注入额外的文件或修改生成的 HTML。
- 优化构建流程:比如压缩文件、处理静态资源、代码分割、缓存等。
- 分析和报告:生成构建过程的报告,帮助开发者了解构建的详细信息。
插件与 Loader 的区别:
- Loader:在构建过程的前期(比如在将源文件转化为模块时)对文件进行处理。它主要用于转换文件,如将 TypeScript 转换为 JavaScript、将 SCSS 转换为 CSS 等。
- Plugin:插件是在 Webpack 构建的整个生命周期中执行的,可以对构建的任何阶段进行自定义修改,范围更广。
Webpack 插件通过与 Webpack 的生命周期钩子(Hooks)交互,能够在不同的构建阶段进行操作。插件通过访问 Webpack 的 Compiler 或 Compilation 对象来执行相关任务。Webpack 的构建过程被划分为多个阶段,每个阶段都有对应的钩子。插件可以在这些钩子上插入自定义逻辑:
- beforeRun:在 Webpack 启动之前执行。
- run:当 Webpack 启动时执行。
- emit:文件生成之前执行,通常用于修改生成的文件。
- done:构建完成后执行,通常用于记录构建结果或生成报告。
Webpack 插件的核心是 apply 方法,这个方法会在插件实例化后被 Webpack 调用。插件通过在 apply 方法中注册自己感兴趣的钩子来参与 Webpack 的构建过程。
class MyPlugin {
// 插件的核心方法:apply
apply(compiler) {
// 通过 compiler 对象访问 Webpack 的生命周期钩子
compiler.hooks.emit.tapAsync('MyPlugin', (compilation, callback) => {
console.log('Webpack is emitting the files...');
// 在 emit 阶段执行一些操作,如修改生成的文件
// 这里是一个异步操作,完成后需要调用 callback 通知 Webpack
callback();
});
}
}
module.exports = MyPlugin;
2
3
4
5
6
7
8
9
10
11
12
13
14
apply(compiler):每个 Webpack 插件都需要实现 apply 方法,它接收一个 compiler 实例,compiler 是 Webpack 编译过程的核心对象,包含了 Webpack 构建的所有信息。compiler.hooks:Webpack 提供了丰富的生命周期钩子,通过 compiler.hooks 可以注册钩子,例如 emit、done、compilation 等。tapAsync和tap:tap 是同步钩子,tapAsync 是异步钩子,允许在执行插件时使用回调或 Promise。
# Webpack 异步加载
Webpack 异步加载原理是实现路由懒加载的基础。
- Webpack 懒加载有什么效果,如何达到懒加载的效果
- Webpack 默认分包及常用的代码分割方式
- Webpack 中懒加载的原理是什么
# 什么是懒加载
懒加载或者按需加载,是一种很好的优化网页或应用的方式。这种方式实际上是先把你的代码在一些逻辑断点处分离开,然后在一些代码块中完成某些操作后,立即引用或即将引用另外一些新的代码块。这样加快了应用的初始加载速度,减轻了它的总体体积,因为某些代码块可能永远不会被加载。
以 Vue 为例,Vue 是单页面应用,可能会有很多的路由引入 ,这样使用 webpcak 打包后的文件很大,当进入首页时,加载的资源过多,页面会出现白屏的情况,不利于用户体验。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应的组件,这样就更加高效了。这样会大大提高首屏显示的速度,但是可能其他的页面的速度就会降下来。对于每个路由都使用懒加载的方式引入,则每个模块都会被单独打为一个 js,首屏只会加载当前模块引入的 js。
所以,懒加载的本质实际上就是代码分离。把代码分离到不同的 bundle 中,然后按需加载或并行加载这些文件。
# 懒加载的实现
首先回顾 Webpack 的默认分包策略:
- Entry Chunk:同一个 entry 下触达到的模块组织成一个 Chunk;
- Async Chunk:异步模块单独组织为一个 Chunk;
- Runtime Chunk:entry.runtime 不为空时,会将运行时模块单独组织成一个 Chunk。
但是默认的分包策略有个弊端:无法解决模块重复。如果多个 Chunk 同时包含同一个 Module,那么这个 Module 会被不受限制地重复打包进这些 Chunk。为此,经常配合 SplitChunksPlugin 实现更高效、智能地实现启发式分包。
而 Webpack 异步加载就是根据 Async Chunk,当涉及到动态代码拆分时,Webpack 提供了两个类似的技术:
- 使用 Webpack 特定的
require.ensure- 不推荐,历史遗留 import()语法实现动态导入 - 推荐
import() 的语法十分简单。该函数只接受一个参数,就是引用模块的地址,并且使用 promise 式的回调获取加载的模块。在代码中所有被 import() 的模块,都将打成一个单独的模块,放在 chunk 存储的目录下。在浏览器运行到这一行代码时,就会自动请求这个资源,实现异步加载。
() => import(`views/${component}`)
# Vue 实现路由懒加载
- 方式一:
() => import()
// import UserDetails from './views/UserDetails'
const UserDetails = () => import(/* webpackChunkName: "group-user" */ './UserDetails.vue')
const router = createRouter({
// ...
routes: [{ path: '/users/:id', component: UserDetails }],
})
2
3
4
5
6
component 配置接收一个返回 Promise 组件的函数,Vue Router 只会在第一次进入页面时才会获取这个函数,然后使用缓存数据。这意味着你也可以使用更复杂的函数,只要它们返回一个 Promise
- 方式二:
(resolve) => require([], resolve)
const router = new Router({
routes: [
{
path: '/list',
component: (resolve) => {
// 这里是你的模块 不用 import 去引入了
require(['@/components/list'], resolve)
}
}
]
})
2
3
4
5
6
7
8
9
10
11
- 方式三:
require.ensure
const List = resolve => require.ensure([], () => resolve(require('@/components/list')),'list');
const router = new Router({
routes: [
{
path: '/list',
component: List,
name: 'list'
}
]
}))
2
3
4
5
6
7
8
9
10
使用 webpack 的 require.ensure 技术,也可以实现按需加载。 这种情况下,多个路由指定相同的 chunkName,会合并打包成一个js文件。
# React 实现路由懒加载
- 方式一:
React.lazy() + Suspense
- 通过
React.lzay()实现组件的动态加载 import()拆包- 优化性能不需要一次加载全部的 js 文件
import { BrowserRouter as Router, Route, Switch } from 'react-router-dom';
import React, { Suspense, lazy } from 'react';
const Home = lazy(() => import('./routes/Home'));
const UserManage = lazy(() => import('./routes/UserManage'));
const AssetManage = lazy(() => import('./routes/AssetManage'));
const AttendanceManage = lazy(() => import('./routes/AttendanceManage'));
const App = () => (
<Router>
<Suspense fallback={<div>Loading...</div>}>
<Switch>
<Route exact path="/" component={Home}/>
<Route path="/userManage" component={UserManage}/>
<Route path="/assetManage" component={AssetManage}/>
<Route path="/attendanceManage" component={AttendanceManage}/>
</Switch>
</Suspense>
</Router>
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 方式二:使用三方包
react-loadable
import React from 'react'
import loadable from 'react-loadable' // 引入这个 loadable,使用这个来加载路由
interface Router {
name?: string,
path: string,
children?: Array<Router>,
component: any
}
const LoadingTip = () => <div>懒加载路由ing...</div>
const router: Array<Router> = [
{
path: '/',
component: loadable({
loader: () => import('@/views/home'), // 需要异步加载的路由
loading: LoadingTip
})
},
{
path: '/about',
component: loadable({
loader: () => import('@/views/about'),
loading: LoadingTip
})
}
]
export default router
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 懒加载实现原理
- 将需要进行懒加载的模块打包成独立的文件(async chunk)
- 借助函数来实现延迟执行模块的加载代码
__webpack_require__.e方法是实现懒加载的核心,在这个方法里面处理了三件事情。
- 使用 JSONP 模式加载路由对应的 js文件,也可以称为chunk。
- 设置 chunk 加载的三种状态并缓存在
installedChunks中,防止chunk重复加载。installedChunks[chunkId]为0,代表该 chunk 已经加载完毕。installedChunks[chunkId]为undefined,代表该 chunk 加载失败、加载超时、从未加载过。installedChunks[chunkId]为Promise对象,代表该 chunk 正在加载。
- 处理 chunk 加载超时和加载出错的场景。
# 懒加载的执行流程
- 运行主程序,加载并执行主包代码
- 点击加载异步模块(懒加载模块)
- 拼接对应模块路径
- 动态插入 script 标签
- 执行 script 脚本,调用 webpackJsonpCallback 方法
- 将懒加载模块注册到
__webpack_modules__中 - 调用模块
# AST 及使用场景
# AST
抽象语法树(Abstract Syntax Tree,AST)是源代码语法结构的一种抽象表示,它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。在代码语法的检查、代码风格的检查、代码的格式化、代码的高亮、代码错误提示、代码自动补全等等场景均有广泛的应用。
Parsing(解析过程):这个过程要经
词法分析、语法分析、构建AST(抽象语法树)一系列操作;Transformation(转化过程):这个过程就是将上一步解析后的内容,按照编译器指定的规则进行处理,
形成一个新的表现形式;Code Generation(代码生成):将上一步处理好的内容
转化为新的代码;
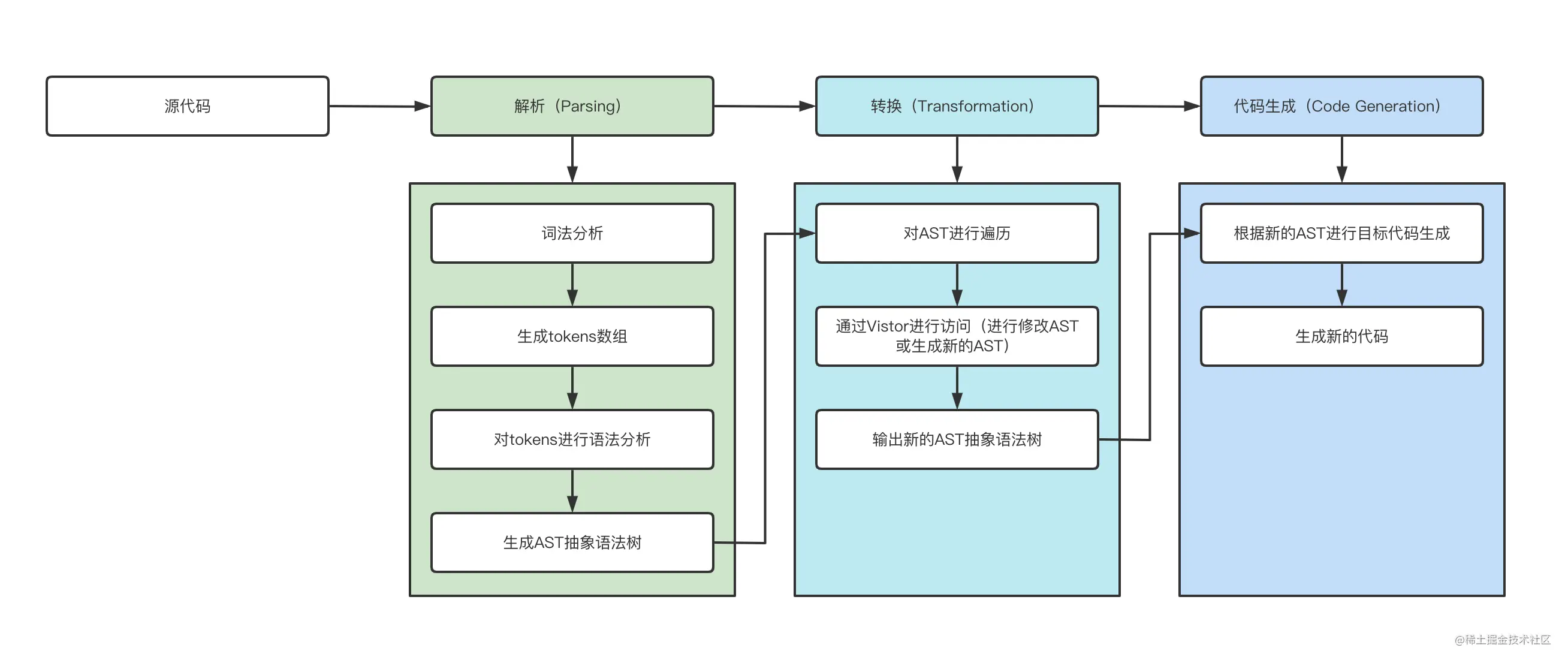
# Babel
解析(@babel/parse):接收代码并输出 AST。 这个步骤分为两个阶段:词法分析(Lexical Analysis) 和 语法分析(Syntactic Analysis)。
code(字符串形式代码) -> tokens(令牌流) -> AST(抽象语法树)- 词法分析阶段把字符串形式的代码转换为 令牌(tokens) 流。
- 语法分析阶段会把一个令牌流转换成 AST 的形式。 这个阶段会使用令牌中的信息把它们转换成一个 AST 的表述结构,这样更易于后续的操作。
转换(@babel/traverse):接收 AST 并对其进行遍历,在此过程中对节点进行添加、更新及移除等操作。
- Babel 提供了
@babel/traverse(遍历)方法维护这 AST 树的整体状态,并且可完成对其的替换,删除或者增加节点,这个方法的参数为原始 AST 和自定义的转换规则,返回结果为转换后的 AST。
- Babel 提供了
生成(@babel/generator):把最终(经过一系列转换之后)的 AST 转换成字符串形式的代码,同时还会创建源码映射(source maps)。
- 深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串。
- 将修改后的 AST 转换成代码,生成过程可以对是否压缩以及是否删除注释等进行配置,并且支持 sourceMap。
# 按需加载原理
- babel-plugin-import
- babel-plugin-component
import { Button } from "antd"
// 经插件转变为
import Button from "antd/lib/Button"
const Button = require("antd/lib/Button")
2
3
4
- 第一步:在插件中拿到我们在插件调用时传递的参数
libraryName - 第二步:获取
import节点,找出引入模块是libraryName的语句 - 第三步:进行批量替换旧节点
# 按需加载插件的实现
第一步:在插件中拿到我们在插件调用时传递的参数 libraryName
const core = require("@babel/core"); //babel核心模块 核心转换引擎
let types = require("@babel/types"); //用来生成或者判断节点的AST语法树的节点
// 节点处理
const visitor = {
ImportDeclaration(path, state) {
const { libraryName, libraryDirectory = "lib" } = state.opts; //获取选项中的支持的库的名称
}
},
};
module.exports = function () {
return {
visitor,
};
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
第二步:获取 import 节点,找出引入模块是 libraryName 的语句
const core = require("@babel/core"); //babel核心模块
let types = require("@babel/types"); //用来生成或者判断节点的AST语法树的节点
const visitor = {
ImportDeclaration(path, state) {
const { libraryName, libraryDirectory = "lib" } = state.opts; //获取选项中的支持的库的名称
+ const { node } = path; //获取节点
+ const { specifiers } = node; //获取批量导入声明数组
+ //如果当前的节点的模块名称是我们需要的库的名称,并且导入不是默认导入才会进来
+ if (
+ node.source.value === libraryName &&
+ !types.isImportDefaultSpecifier(specifiers[0])
+ ) {
+ //xxx
+ }
},
};
module.exports = function () {
return {
visitor,
};
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
第三步:进行批量替换旧节点
const core = require("@babel/core"); //babel核心模块
let types = require("@babel/types"); //用来生成或者判断节点的AST语法树的节点
const visitor = {
ImportDeclaration(path, state) {
const { libraryName, libraryDirectory = "lib" } = state.opts; //获取选项中的支持的库的名称
const { node } = path; //获取节点
const { specifiers } = node; //获取批量导入声明数组
//如果当前的节点的模块名称是我们需要的库的名称,并且导入不是默认导入才会进来
if (
node.source.value === libraryName &&
!types.isImportDefaultSpecifier(specifiers[0])
) {
+ //遍历批量导入声明数组
+ const declarations = specifiers.map((specifier) => {
+ //返回一个importDeclaration节点,这里也可以用template
+ return types.importDeclaration(
+ //导入声明importDefaultSpecifier flatten
+ [types.importDefaultSpecifier(specifier.local)],
+ //导入模块source lodash/flatten
+ types.stringLiteral(
+ libraryDirectory
+ ? `${libraryName}/${libraryDirectory}/${specifier.imported.name}`
+ : `${libraryName}/${specifier.imported.name}`
+ )
+ );
+ });
+ path.replaceWithMultiple(declarations); //替换当前节点
}
},
};
module.exports = function () {
return {
visitor,
};
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 泛型场景
function join<T, W>(a: T, b: W) {}
join < number, string > (1, "2");
2
整体思路:
- 第一步:先获取实参类型数组(1,'2'的类型数组:
[number,string]) - 第二步:获取函数调用时传递的泛型类型数组(
[number, string]) - 第三步:拿到函数定义时的泛型 [ T , W ],然后结合第二步将 T 赋值为 number,W 赋值为 string,得到数组
[T=number,W=string] - 第四步:计算函数定义时的形参类型数组:此时
a:number,b:string => [number,string] - 第五步:a 的形参类型跟 a 的实参类型进行比较,b 的形参类型跟b的实参类型进行比较
# 文件监听及原理
Webpack 会轮询判断文件的最后编辑时间是否变化,当某个文件发生了变化,并不会立刻告诉监听者,而是先缓存起来,等 aggregateTimeout。
module.export = {
// 默认 false,也就是不开启
watch: true,
// 只有开启监听模式时,watchOptions 才有意义
watchOptions: {
// 默认为空,不监听的文件或者文件夹,支持正则匹配
ignored: /node_modules/,
// 监听到变化后会等 300ms 再去执行,默认 300ms
aggregateTimeout: 300,
// 判断文件是否发生变化是通过不停询问系统指定文件有没有变化实现的,默认每秒(1000ms)询问 1 次
poll: 1000,
},
};
2
3
4
5
6
7
8
9
10
11
12
13
每次都要刷新,有没有方法监听变化后,自动更新 -> 热更新。
Webpack 轮询会调用 Node.js 里面的文件读取 API fs 这个模块来判断文件内容是否变化。
# 文件指纹与缓存
# 文件指纹
如果不利用文件指纹是无法有效利用客户端级别的缓存,因为无法判断文件是否已更改。可以通过在文件名中包含哈希来实现缓存失效。
文件指纹通常有两个用途:
- 版本管理: 在发布版本时,通过文件指纹来区分 修改的文件 和 未修改的文件。
- 使用缓存: 未修改的文件,文件指纹保持不变,浏览器继续使用缓存访问。
文件指纹策略作用于服务的增量更新。
增量更新是指在进行更新操作时,只更新需要改变的地方,不需要更新或者已经更新过的地方则不会重复更新,增量更新与完全更新相对。这种更新的概念应用范围比较广泛,凡是需要进行数据更新的地方都会用到,如软件更新、数据库更新、杀毒软件的病毒库更新、CMS 更新和路由表更新等。
Webpack 为此提供占位符。这些字符串用于将特定信息附加到 Webpack 输出。
[hash]:和整个项目的构建相关,只要项目文件有修改,整个项目构建的hash值就会更改。即,compilation实例的变化就会触发 Hash 的变化[chunkhash]:和 Webpack 打包的chunk有关,不同的entry会生成不同的chunkhash值(由于采用chunkhash,所以项目主入口文件main.js及其对应的依赖文件main.css由于被打包在同一个模块,所以共用相同的chunkhash,但是公共库由于是不同的模块,所以有单独的chunkhash,这样就保证了在线上构建时只要文件内容没哟 u 更改就不会重复构建)[contenthash]:根据文件内容来定义hash,文件内容不变,则contenthash不变。一个页面内的 JS 内容、CSS 内容都会拥有自己的 Contenthash,可以保持各自的独立更新。
前两者 hash 和 chunkhash 仅用于生产目的,因为哈希值在开发期间没有太大的用处。在实际在项目中,我们一般会把项目中的 css 都抽离出对应的 css 文件来加以引用。如果我们使用 chunkhash,当我们改了 css 代码之后,会发现 css 文件 hash 值改变的同时,js 文件的 hash 值也会改变。所以,要用 contenthash 。
使用 contenthash 时,往往会增加一个小模块后,整体文件的 hash 都发生变化,原因为Webpack 的 module.id 默认基于解析顺序自增,从而引发缓存失效。具体可通过设置 optimization.moduleIds 设置为 'deterministic' 。
# 缓存实践
缓存的意义就在于减少请求,更多地使用本地的资源,给用户更好的体验的同时,也减轻服务器压力。所以,最佳实践,就应该是尽可能命中强缓存,同时,能在更新版本的时候让客户端的缓存失效。
在更新版本之后,如何让用户第一时间使用最新的资源文件呢?机智的前端们想出了一个方法,在更新版本的时候,顺便把静态资源的路径改了,即,可以利用 webpack 的文件指纹策略。这样,就相当于第一次访问这些资源,就不会存在缓存的问题了。
一个较为合理的缓存方案:
- HTML 频繁更新的资源:使用协商缓存。
- 假设 html 使用了强缓存,当我们重新上线 css、js等文件,html文件(因为css改变了,所以html要重新引入css文件,因此html也要改并且重新上线),但是 html 使用的是强缓存,在缓存期间浏览器直接从强缓存中读取html文件,以至于你重新上线了但是还是原来的 html,内容还是原来,必须要用户强制刷新才会有新内容出现,这就不合理。所以不能使用强缓存。
- CSS、JS、图片等静态稳定资源:使用强缓存,且文件命名带上 hash 值。
- 更新资源发布路径以实现非覆盖式发布,使强缓存失效。
- 利用版本号更新策略可行吗?
<link rel="stylesheet" href="/index.css?v=1.0.2">在后面加个版本号,因为每次 html 都会发送请求询问是否过期,所以就可以达到缓存更新效果。但是开发不可能就引用一个 css 文件,往往是多个的。每次修改一个css 文件,其余的版本也要跟着升级,没有必要。
既然可以使用协商缓存的 Etag,那有必要使用文件指纹吗?
- 缓存的意义。缓存的意义就在于减少请求,更多地使用本地的资源,给用户更好的体验的同时,也减轻服务器压力。所以,最佳实践,就应该是尽可能命中强缓存,同时,能在更新版本的时候让客户端的缓存失效,访问最新资源,那么就需要文件指纹、版本号等使强缓存失效的手段。
- CSS、js、图片、字体等资源要做强缓存。利用 Webpack 合理分包加上文件指纹做到客户端的持久化缓存,不去解析 DNS,不去请求服务器,减小服务端压力的同时提高用户体验。所以,文件指纹用于资源路径更新使缓存失效,达到及时拉取最新资源的目的,使用文件指纹和 Etag 没什么关系。
- 分布式服务不使用 Etag。分布式服务,Etag 是关闭的,因为每台机器生成的 ETag 都会不一样。
- 持久换缓存做无覆盖式更新。CSS、js、图片、字体等资源不需要做协商缓存,不需要每次请求服务器询问资源是否新鲜。只需要 hrml 做协商缓存即可。若发布了最新资源,由于 html 中引用的资源的路径变了,会拉取最新资源,做无覆盖式更新。
总之一句话,为减少服务器请求,资源要尽可能做强缓存,而资源的更新需要利用文件指纹变更资源路径使强缓存失效,从而达到及时拉取到最新资源的目的。所以,文件指纹是为强缓存资源服务的,与协商缓存 Etag 无任何关系。
# 缓存更新问题
一个较为合理的缓存方案:
- HTML 频繁更新的资源:使用协商缓存。
- CSS、JS、图片等静态稳定资源:使用强缓存,且文件命名带上 hash 值。
# 缓存更新方式一:给静态资源加版本号 - 通过 query 加版本号:foo.css?v=002
优点:统一加版本号的优点是简单粗暴快捷。 缺点:假如我们只想更新 foo.css,但 bar.css 缓存也失效了,又造成了带宽的浪费。
# 缓存更新方式二:将文件内容与版本号(URL)绑定 - 通过 query-hash 精准缓存控制:foo.css?v=gesd8393
考虑极端情况。那就是:
- 先部署静态资源,部署期间访问时,会出现 V1 版本 HTML 访问到 V2 版本新静态资源,并按
V1-hash缓存起来。 - 先部署 HTML,部署期间访问时,会出现 V2 版本 HTML 访问到 V1 版本旧静态资源,并按
V2-hash缓存起来。
上面方案的问题起源于静态资源只有一份,每次发布时都是覆盖式发布,导致页面与静态资源出现匹配错误的情况!解决问题方案也极其简单,使用非覆盖式发布:即将 query-hash 改为 name-hash
# 缓存更新方式三:利用文件指纹并非覆盖式发布
每次部署时先全量部署静态资源,再灰度部署页面,此时,服务器上会存在多份 foo.[$hash].css 文件,就能比较完美的解决了缓存的问题。
# 前端部署流程与设计
# 静态资源组织
- 为了最大程度利用缓存,将页面入口(
HTML)设置为协商缓存,将JavaScript、CSS等静态资源设置为永久强缓存。 - 为了解决强缓存更新问题,将文件摘要(
hash)作为资源路径(URL)构成的一部分。 - 为了解决覆盖式发布引发的问题,采用
name-hash而非query-hash的组织方式,具体需要配置Wbpack的output.filename为contenthash。 - 为了解决
Nginx目录存储过大 + 结合CDN提升访问速度,采用了Nginx 反向代理+ 将静态资源上传到CDN。 - 为了上传
CDN,我们需要按环境动态构造publicPath+ 按环境构造CDN上传目录并上传。 - 为了动态构造
publicPath并且随构建过程插入到HTML中,采用Webpack-HTML-Plugin等插件,将编译好的带hash+publicPath的静态资源插入到HTML中。 - 为了保证上传
CDN的安全,我们需要一种机制管控上传CDN秘钥,而非简单的将秘钥写到代码 /Dockerfile等明文文件中。
# 自动化构建
- 拉取远程仓库
- 切换到 XX 分支
- 代码安全检查(非必选)、单元测试等等
- 安装
npm/yarn依赖- 设置
node版本 - 设置
npm/yarn源 - 安装依赖等
- 设置
- 执行编译 & 构建
- 产物检查(比如检测打包后
JS文件 / 图片大小、产物是否安全等,保证产物质量,非必选) - 人工卡点(非必选,如必须
Leader审批通过才能继续) - 打包上传
CDN - 自动化测试(非必选,
e2e) - 配套剩余其他步骤
- 通知构建完成
业界有一些解决方案:
- 保证环境一致性:Docker (opens new window)
- 按流程构建:Jenkins (opens new window)
- 自动化构建触发:Gitlab webhook (opens new window) 通知
- 开始构建通知:依赖账号体系打通+ Gitlab Webhook
- 构建完成通知:依赖账号体系打通
业界的大致实现,一般都为 Jenkins + Docker + GitlabWebHook。为了提升部署效率,100% 避免因部署出错,需要设计 & 搭建自动化部署平台,以 Docker 等保证环境的一致性,以 Jenkins 等保证构建流程的串联。使用 es-build 等提升构建效率。
# 发布部署
前端发布服务应该包含:
- 环境隔离(环境标:测试、预发、生产)
- 流量控制(小流量测试,ABTest、灰度上线)
- 版本管理(秒级回滚、版本切换)
# 环境隔离与流量控制的常见实现方案
我们的静态资源为非覆盖式发布,多次部署后,线上存在若干版本静态资源。实现Pre环境/灰度上线的思路则是:
通过一定的机制,让特定用户访问特定静态资源版本,从而达到访问Pre/灰度上线的能力。
# 方案一: Nginx 层动态转发
静态资源部署多个版本后,开发者的通过 ModHeader 等浏览器插件,在请求中携带特定 Header(如xx-env=pre),在 Nginx 层消费该 Header 并动态转发到对应环境的静态资源上,实现访问不同环境下的静态资源。此时,除静态资源为特定版本外,所有环境都是生产环境,可以将变量范围控制在最小。
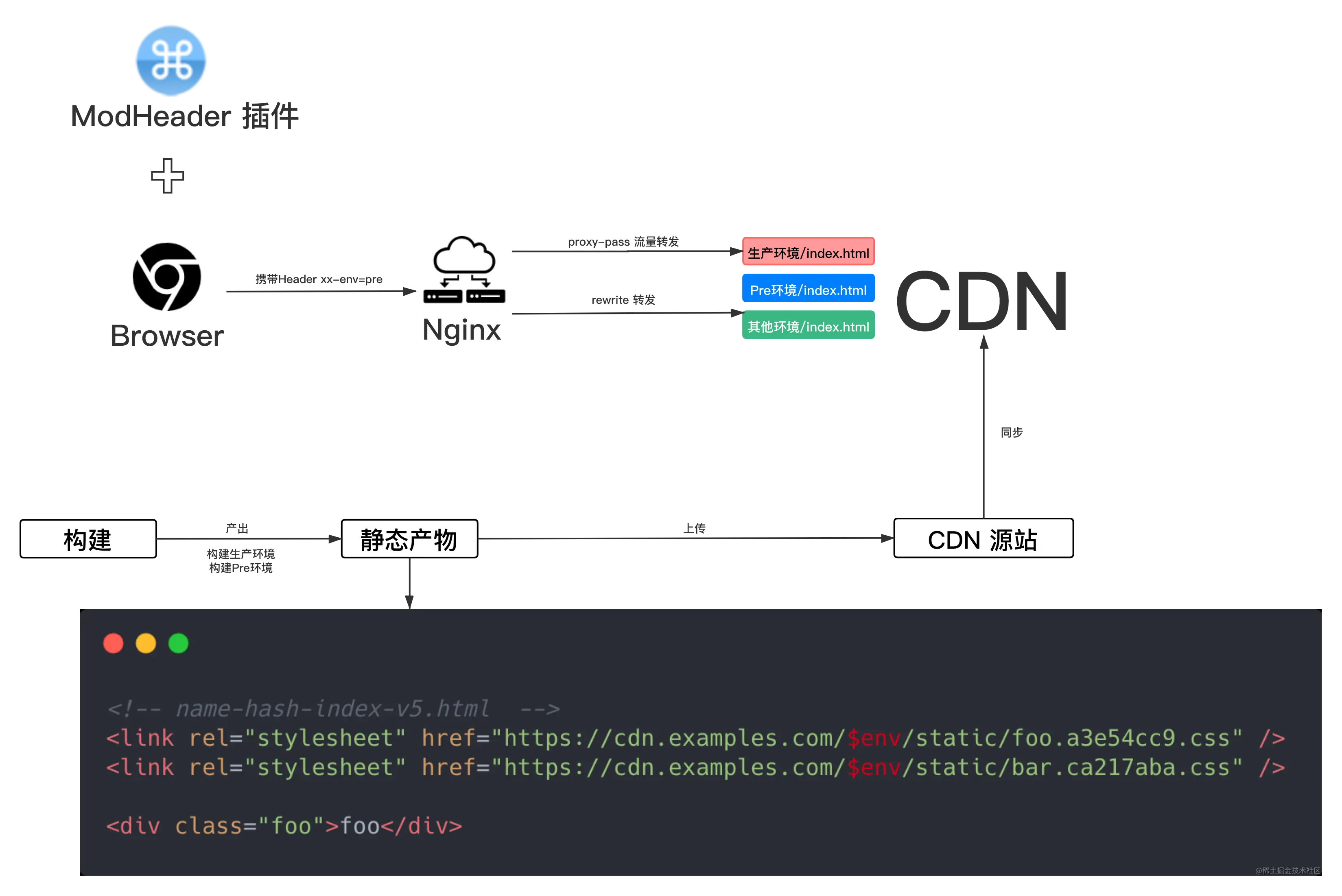
Nginx 可通过配置 rewrite 设置转发:
location /example {
rewrite ^ $cdn/$http_x_xx_env/index.html break;
proxy_pass $cdn/prod/index.html;
}
# $http_x_xx_env 表示取自定义的 Request Header 字段 xx_env
2
3
4
5
6
优点:配置简单高效,适用于工程师。 缺点:每个用户都需要手动配置,不适用于移动端,且无法让特定用户被动精确访问某版本,配置 Header 成本过高。
同理,也可以在 Nginx 层按一些其他规则处理,实现灰度上线的能力。
- 如通过一定随机数 rewrite,达到小范围随机灰度。
- 获取 user-agent 并 rewrite,达到按浏览器定向灰度。
- 通过 Nginx GeoIP 获取地域信息,达到按地域灰度。
但上述灰度方案配置复杂,而灰度比例 / 范围往往会配置较多,每次上线都需要运维登陆生产服务器修改,较容易出各种事故。故不推荐使用,仅供拓宽思路。
# 方案二:动态配置 + 服务端转发
而为了能随时随地调整灰度 / Pre 策略,而非依赖调整代码发版上线,此时引入配置中心的概念。
配置中心:
一般是独立的平台 / SDK,提供动态配置管理的解决方案,提供功能有配置管理、版本管理、权限管理、灰度发布等等。后端应用通过接口消费,故配置中心和后端解耦,可以随时修改调整配置而非重新发版。 配置中心一般是配置一个 JSON 对象。 配置中心JSON对象人工维护容易引发问题,故增加机器人来降低出错几率。
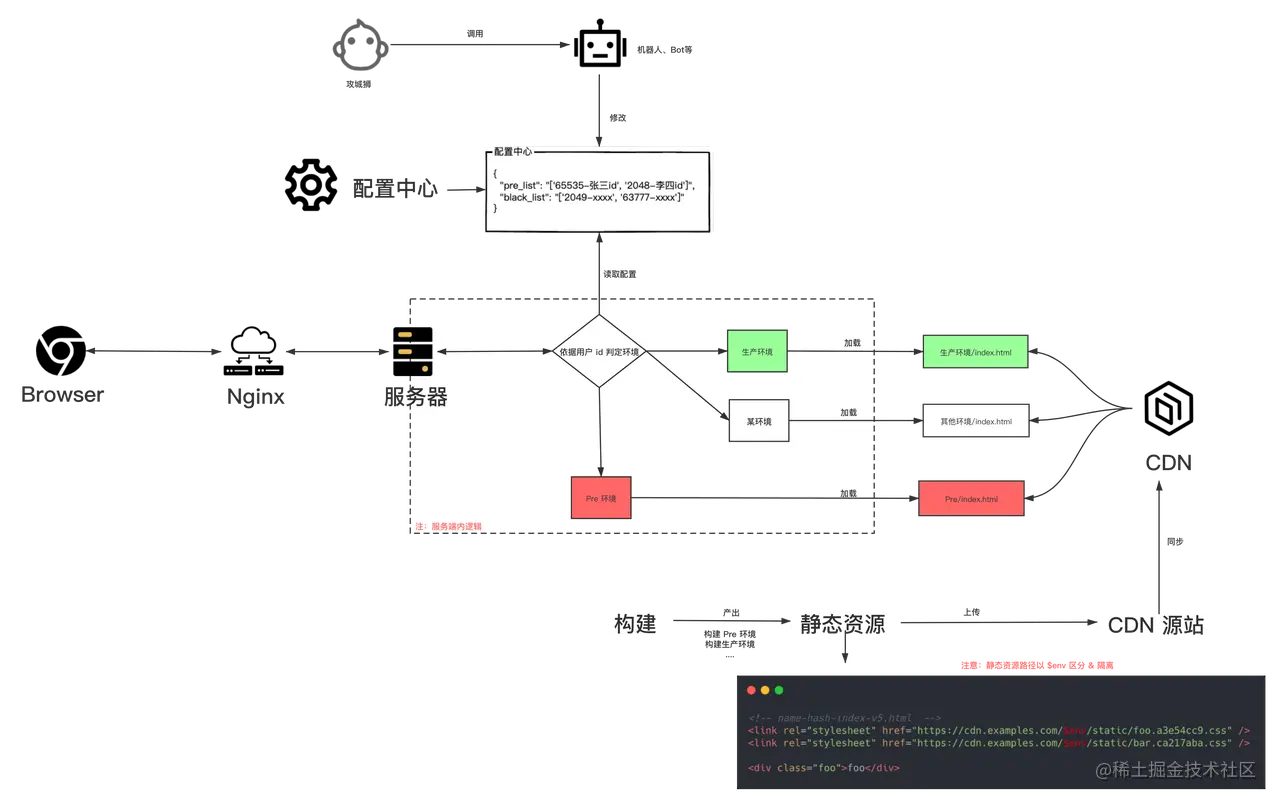
主要流程为:
- 前端部署多个版本静态资源到 CDN 上(问题?如何管控多版本静态资源?)。
- 后端收到请求后,通过各种 Proxy 层将 Cookie 转换成用户信息。
- 后端读取配置中心数据,依据用户信息判断给用户访问什么环境,加载具体环境 index.html
- 后端返回给浏览器加工后的 index.html
- 若需添加特定用户到 Pre 名单,只需调用机器人/Bot 等,修改配置中心,即可生效。
此时,一些小流量配置,AB实验,版本管理其实也可以通过该方案实施。
优点:可以随时调整,不用后端发版,移动端也可生效。 缺点:
- 和服务端强绑定(要求用户信息,在所难免)。
- 每次都需要从
CDN加载HTML, 有一定性能浪费。但若缓存HTML,发版环节还要通知服务端,总体增加复杂度。 - 若考虑
CDN故障,服务端做CDN降级会增加复杂度。 - 版本管理 / 小流量等为通用需求,而该方案每个后端应用都需要开发或接入。
- 常见的配置中心又一般为
JSON配置,比较简陋,和发版的多环境无法关联,依赖人为配置,有出错的风险(如发版v1.2501,配置中心手动配置时手误改成了v1.2051)。
# 前端发布服务实现与设计
上述只是几种环境管理,流量控制实现的几种常见方案,但在实际工程中或多或少有些缺陷。
版本管理/小流量是前端部署的常见公共业务需求,应该和业务后端服务脱离,故这里提出一个新的公共服务,纯用于前端部署相关,此处将之称为 Page Server,用于具体的 index.html 文件管理 & 承接 Nginx 流量或业务后端流量等。
同时,鉴于版本管理、小流量策略等调整会特别频繁,每次调整不应该都登录服务器,故我们需要一个新的服务 & 界面,用于操作管理版本、调整小流量等信息,并且与上述 Page Server 同步,此处我们将该服务称之为 Page Config Web。
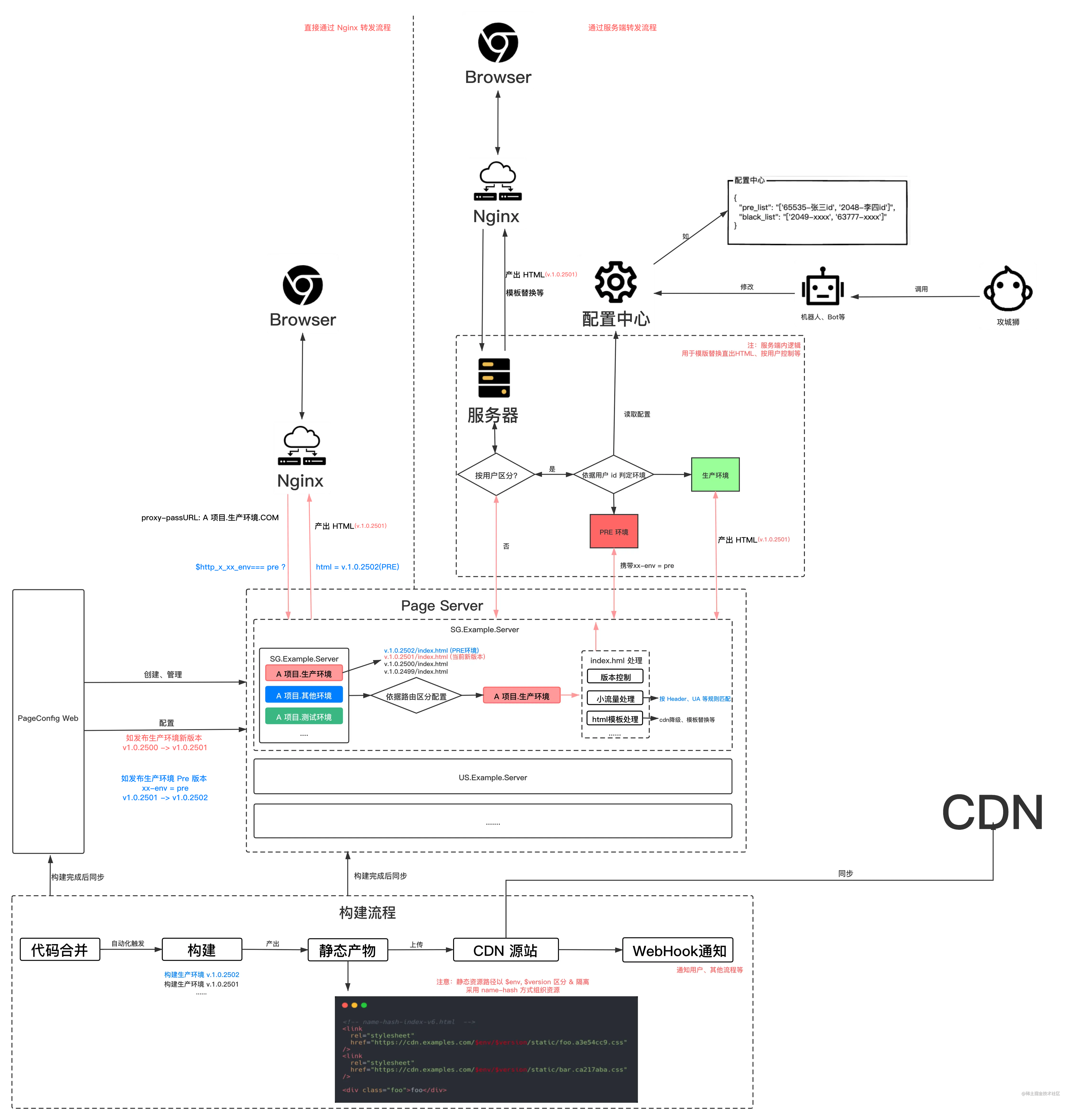
本质上来说,相当于有一个公用的中间服务,部署在多个集群上,与构建发布过程深度绑定,用于承接HTML 的流量,并通过 Web 站点设置小流量规则、版本等等,来满足多变的上线需求。
其中,PageServer 在承载 HTML 服务时,可做一些其他工作,比如:
- SSR
- CDN 降级,用于 CDN 异常时直出 HTML 中将静态资源替换为可用的 CDN 站点。
- 404 处理
- 兜底页(比如服务出现故障,短时间内无法修复时出兜底)
- 模板渲染(如做模板替换,将 query 替换到模板中等)
- 特殊时期全局处理,如注入全局样式将页面全局置灰
PageConfig Web 和 PageServer 中有构建后的所有版本信息,理论上可以缓存每个版本的 HTML文件,并且为了优化性能,PageServer 中可将最新全量版本的 HTML 文件缓存到内存中,最大程度提升响应速度,其余版本存储到 Redis 等缓存中。
下面以发布一个正式版本 v.1.0.2502 并且回滚过程为例:
- 代码合并,触发自动化构建,构建产物以环境(env)+版本(env) + 版本(env)+版本(version) + name-hash 方式组织,并上传到 CDN。
- 构建完成后,构建脚本通知攻城狮同学、同步 PageServer、PageConfig Web 服务有新版本 v.1.0.2502 。
- 攻城狮同学收到通知后,到 PageConfig Web 站点发布新版本 v.1.0.2502 (PRE),并为该版本配置 PRE 环境小流量规则,
xx-env = pre。此时,只有设置特定 Header 才能访问该版本。 - 若是 Nginx 直接转发,则攻城狮通过设置 Header 访问 PRE 版本。
- 若是通过服务端转发,攻城狮通过配置中心设置 PRE 白名单,即可让用户访问 PRE 版本。
- 在 PRE 版本验收完成后,攻城狮登录 PageConfig Web 站点,发布正式版本 v.1.0.2502 (不带小流量信息)。此时立即生效。
- 生效后线上回归,发现有 bug,攻城狮立马登录 PageConfig Web 站点,将版本回滚为上一版本v.1.0.2501 。此时立即生效。
关于前端部署,能总结出下面几个原则/要求:
构建发布后,不应该被覆盖。
构建发布后,静态资源应当永久保存在服务器/CDN 上,即只可读。
静态资源组织上,每个版本应该按文件夹存储,做到资源收敛。这样假如真要删除时,可按版本删除。(如某个版本代码泄密)
发布过程应该自动化,开发人员不应该直接接触服务器。
版本切换时,也应当不接触服务器。
版本切换能秒级生效。(如 v0.2 切换 v0.3,立即生效)。
线上需要能同时生效多个版本,满足 AB 测试、灰度、PRE 环境等小流量需求。
# 问题
# Q1. 如何避免前端上线,影响未刷新页面的用户?
使用文件指纹方式组织静态资源,先上线静态资源,再上线 HTML。
# Q2. 刚上线的版本发现有阻塞性 bug,如何做到秒级回滚,而非再次部署等 20 分钟甚至更久?
HTML 文件使用非覆盖方式存储在 CDN 上,搭建前端发布服务,对 HTML 按版本等做缓存加工处理。当需要回滚时,更改发布服务 HTML 指向即可。
# Q3. CDN 域名突然挂了,如何实现秒级 CDN 降级修补而非再次全部业务重新部署一次?
将静态资源传输到多个 CDN 上(分布式 CDN),并开发一个加载 Script 的 SDK 集成到 HTML 中。当发现 CDN 资源加载失败时,逐步降级 CDN 域名。在前端发布服务中,增加 HTML 文本处理环节,如增加 CDN 域名替换,发生异常时,在发布服务中一键设置即可。
# Q4. 如何实现一套前端代码,发布成多套环境产物?
使用环境变量,将当前环境、CDN、CDN_HOST、Version等注入环境变量中,构建时消费 & 将产物上传不同的 CDN 即可。
# Q5. 前端代码从 tsx/jsx 到部署上线被用户访问,中间大致会经历哪些过程?
经历本地开发、远程构建打包部署、安全检查、上传 CDN、Nginx做流量转发、对静态资源做若干加工处理等过程。
← Tree Shaking 模块化规范 →